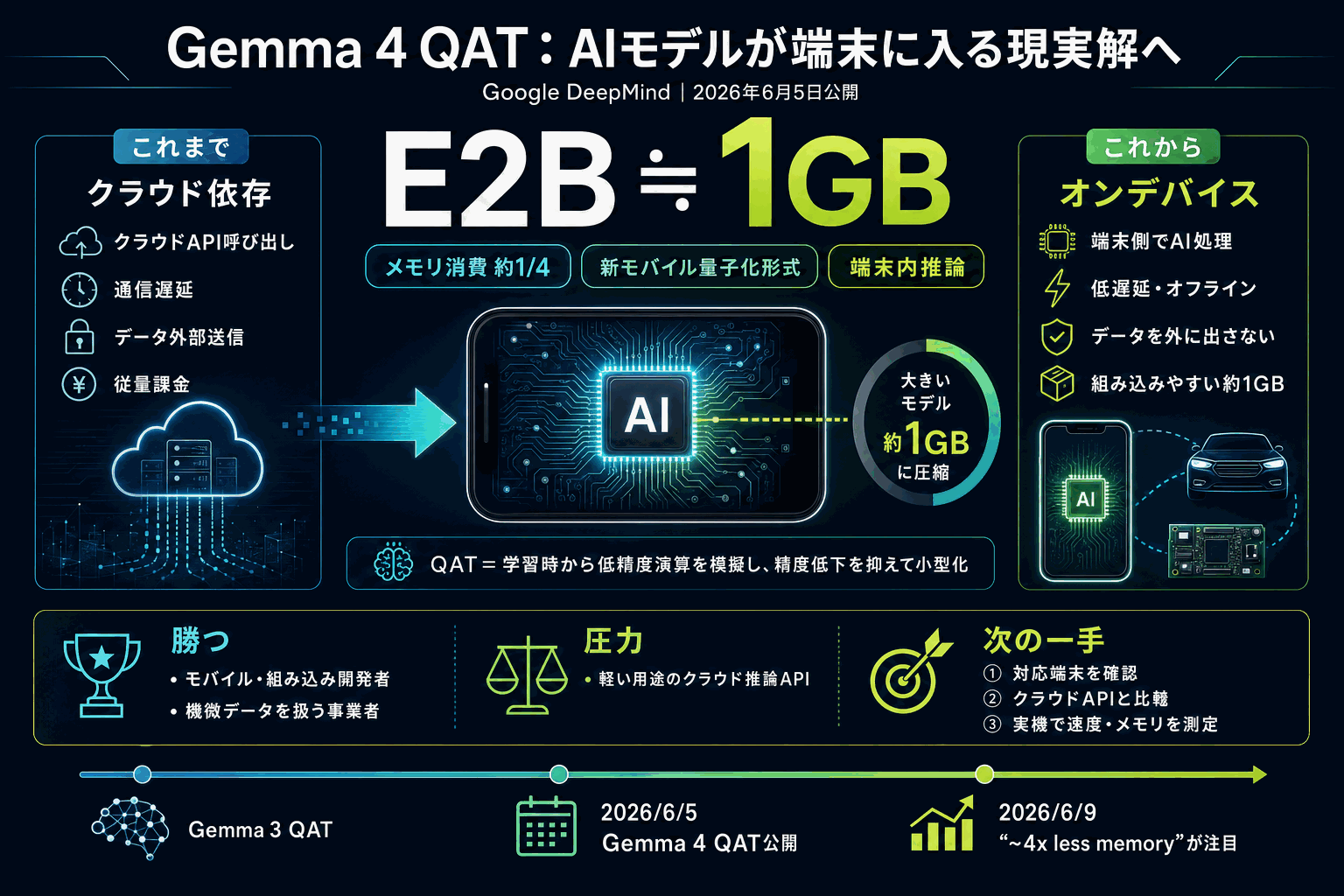
Google DeepMindが2026年6月5日、軽量AIモデル「Gemma 4」に量子化を意識した学習(QAT)を適用したチェックポイントを公開した。新しいモバイル向け量子化形式により、E2Bモデルのメモリ消費を約1GBまで削減し、性能をほぼ保ったままメモリ使用量を約4分の1に抑えたとしている。一次発表元はGoogle DeepMindの公式ブログである。
QATは、モデルの数値表現を粗くして容量を減らす手法を学習段階から織り込む技術で、後から圧縮する方式に比べて精度低下を抑えやすい。前世代のGemma 3でも家庭用GPU向けにQAT適用モデルが配布されており、今回はその流れをモバイル端末まで広げ、具体的な数値とともに正式チェックポイントとして配った点が新しい。
モデルが約1GBに収まることで、クラウドに送らず端末側でAIを動かす用途が現実的になる。通信を介さないため遅延やデータの外部送信を避けたい構成で有利になり、モバイルアプリや組み込み機器へのAI搭載を検討する開発者の選択肢が広がる。容量と精度のバランスを示す数値が公式から出たことが、導入判断の材料になる。