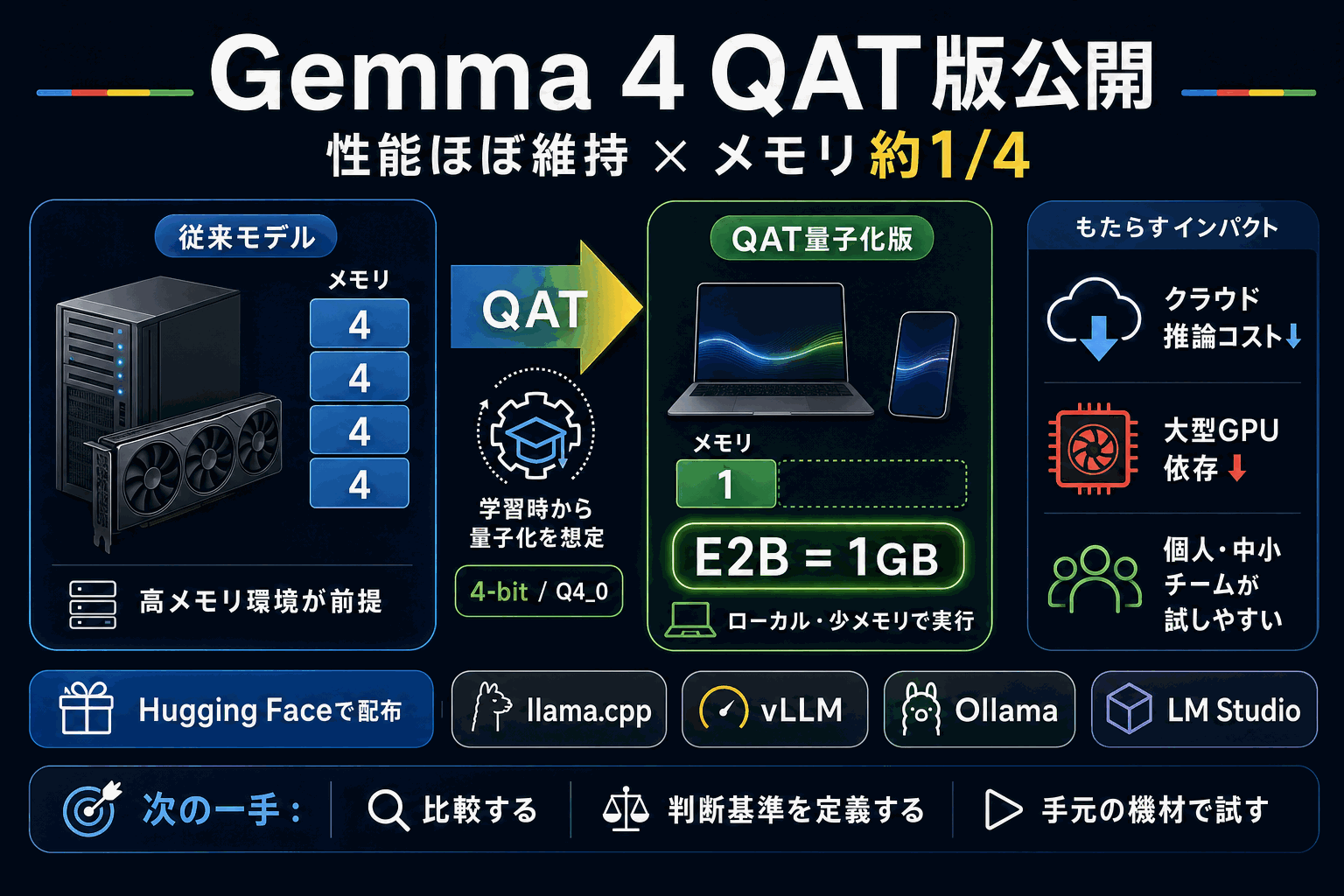
GoogleがGemma 4向けに、量子化対応学習(QAT)で作成した新しいモデルチェックポイントを公開した。性能をほぼ維持したまま、消費メモリを従来の約4分の1に削減できるのが特徴である。新しいモバイル向け量子化形式により、小型モデルのGemma 4 E2Bはわずか1GBのメモリで動かせるようになった。
チェックポイントは4ビット(Q4_0)形式やモバイル向け形式でHugging Faceに配布される。実行ツールはllama.cpp・vLLM・Ollama・LM Studioに対応し、新しい環境を組み直さずに手元のツールで読み込める。QATは学習中に低精度演算を模擬することで、圧縮後の精度低下を抑える手法である。
メモリ要件が下がることで、これまで大型GPUが必要だったモデルを少メモリ環境やローカル端末でも動かしやすくなる。個人や中小規模のチームが追加投資なしで手元の機材で利用でき、クラウド推論コストを払わずにオンデバイスで動かす選択肢が現実的になった。