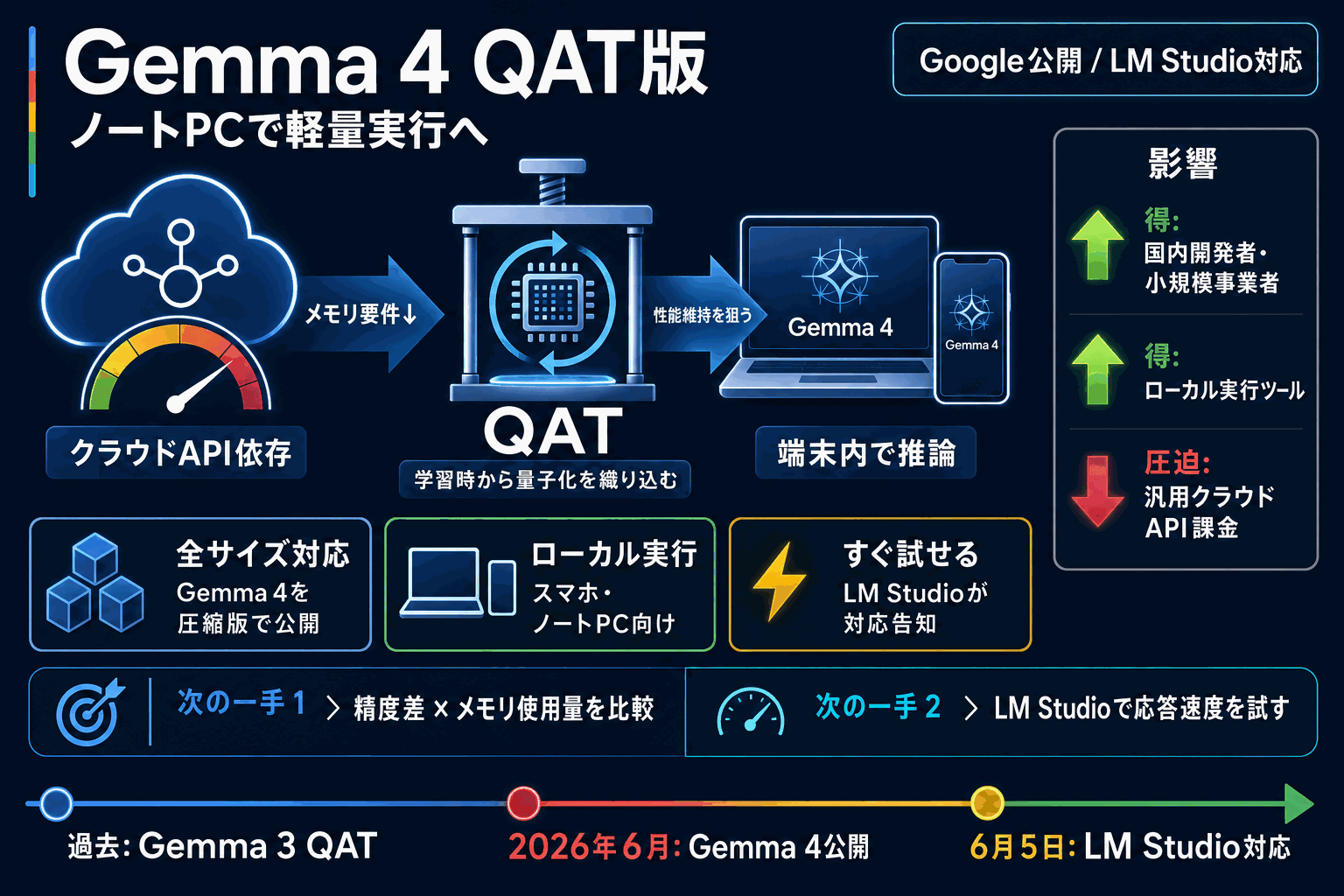
Googleがオープンモデル「Gemma 4」の全サイズに量子化対応学習(QAT)を適用した圧縮版を公開した。QATは学習段階からデータ圧縮を前提に訓練する手法で、訓練後に単純圧縮する場合より精度低下を抑えられる。狙いはスマートフォンやノートPCといった限られた計算資源での動作効率向上にある。一次発表元はGoogle公式ブログで、ローカル実行ツールLM Studioは2026年6月5日に対応を告知した。
Gemma 4はこの量子化版を含む大きなアップデートで、画像なども扱える統合型マルチモーダルの12Bモデルや、複数単語予測による推論高速化など複数の技術を含む。メモリ削減と推論高速化が、手元の端末で動かすという同じ目的に向かっている。
クラウドのAPI課金に頼らず端末上で高性能モデルを動かす選択肢が広がる。オープンモデルとして配布されるため自前環境に組み込みやすい。ただし「性能を保つ」とうたわれていても、自社タスクでの精度差・メモリ占有・速度は手元で測って判断する必要がある。