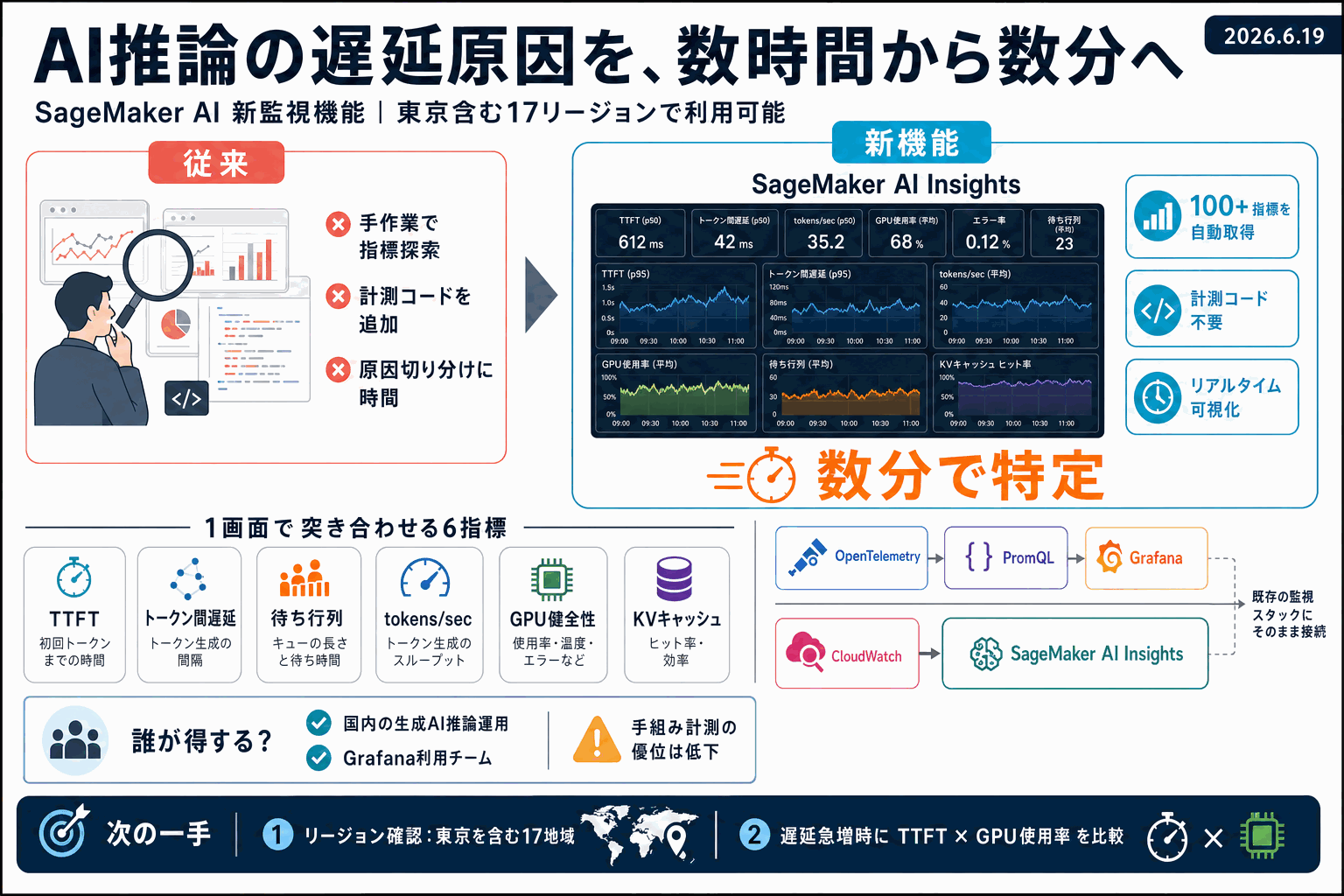
AWSは機械学習基盤Amazon SageMaker AIに、生成AI推論エンドポイントの稼働状況を実時間で見える化する新しい監視機能を追加した。最初の応答までの時間(Time to First Token)、トークン間遅延、待ち行列の深さ、毎秒トークン数を追跡し、GPUの健全性と並べて表示することで、応答が遅い原因を数時間でなく数分で特定できる。
中核は、CloudWatch上に標準で用意される専用ダッシュボード「SageMaker AI Insights」。GPU使用率、推論コンポーネントの配置数、拡張イベント、起動遅延(コールドスタート)の内訳を1画面で確認できる。計測コードの追加が不要で、業界標準のOpenTelemetry形式の指標を自動出力する。PromQL対応エンドポイント経由でGrafanaなど既存の監視ツールにも直接接続できる。
東京・ソウル・シンガポールを含む17のAWS地域で利用可能で、国内で推論基盤を運用する事業者にとって、東京リージョンで初日から使える点が導入判断の前提となる。