コンテキストウィンドウの「壁」を回避する新しい設計
AWSが公開した今回のブログは、LLMアプリケーション開発における長年の課題、すなわちコンテキストウィンドウの上限に対する実装パターンを示すものだ。従来は入力できるトークン数を超える文書を扱う場合、RAG(検索拡張生成)でチャンク分割して関連箇所のみを取り出す方式が主流だった。しかし関連性判定の精度や、文書全体を俯瞰する必要があるタスクでは限界もあった。
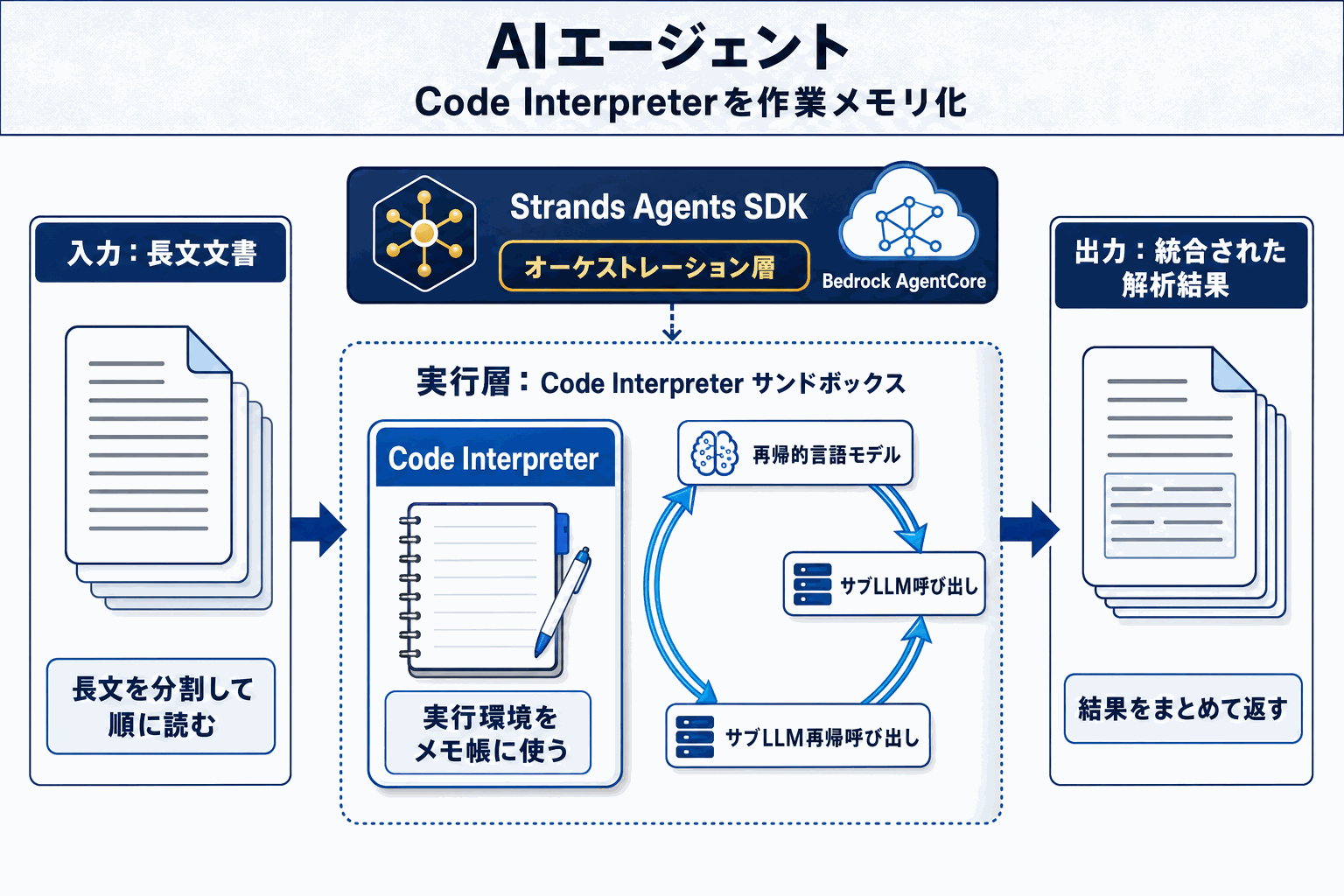
今回提示されたRecursive Language Models(RLM)は、Amazon Bedrock AgentCoreのCode Interpreterを「永続的な作業メモリ」として使い、サンドボックス化されたPython環境内からサブLLM呼び出しをオーケストレーションする構成だ。文書セクションごとにサブLLMを再帰的に呼び出し、結果をコード実行環境上に保持しながら反復的に解析を進める。
Strands Agents SDKとの統合と実装上の含意
実装にはStrands Agents SDKが組み合わされている。これによりエージェントのオーケストレーション層と、Code Interpreterによる実行層が明確に分離され、文書長に応じた処理戦略をコード側で柔軟に記述できる。
読者が実装に着手する際の落とし穴として、サブLLM呼び出しのコスト管理がある。再帰的にLLMを呼び出す構造は、文書が長くなるほど呼び出し回数が増え、トークン課金も累積する。AWS公式ブログでは具体的なコスト数値は示されていないため、PoC段階で文書サイズと呼び出し回数の関係を実測することが必須になる。また、Code Interpreterのサンドボックス内で扱うデータの永続性とセッション境界も、本番運用前に切り分けが必要な領域だ。
By the end, you will know how to process documents of varying lengths, with no upper bound on context size, use Bedrock AgentCore Code Interpreter as persistent working memory for iterative document analysis