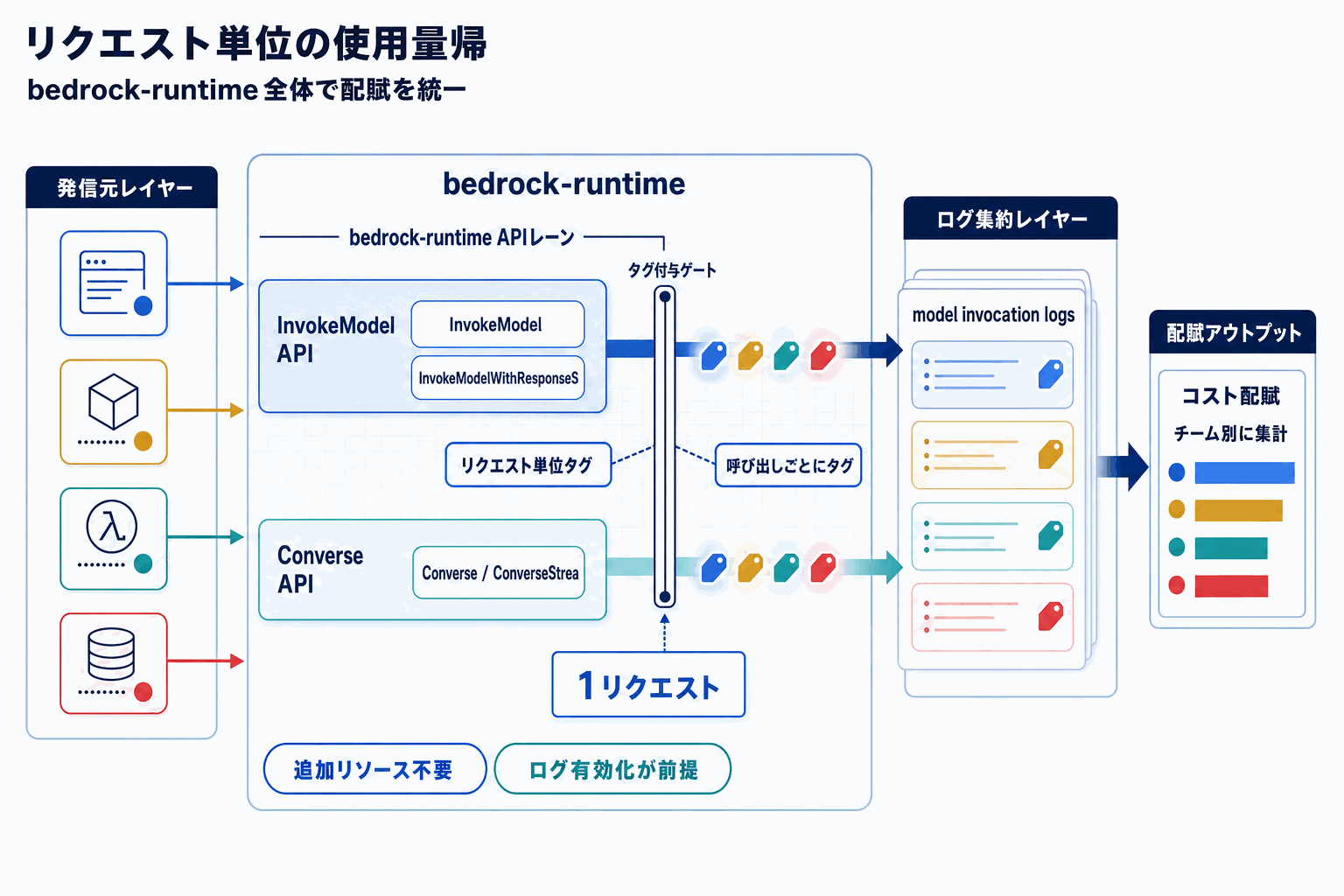
何が変わったのか
Amazon Bedrockは、InvokeModelおよびInvokeModelWithResponseStream APIにおいて、推論リクエスト1件ごとにチーム名・アプリケーション名・環境・実験名などのメタデータをタグ付けできるようにした。タグ付けされた使用量はAmazon Bedrockのモデル呼び出しログ(model invocation logs)から、タグ別に分析できる。利用にあたっての前提条件は、Bedrockを呼び出すAWSリージョンでモデル呼び出しロギングを有効化することのみで、新たなリソースのプロビジョニングは不要だ。
公式発表は次のように位置づけている。
Today's release brings the same capability to the InvokeModel and InvokeModelWithResponseStream APIs, giving customers a consistent way to tag inference calls across the entire bedrock-runtime endpoint.
なぜ今これが効くのか
Bedrockの使用量帰属はこれまで、application inference profile、IAMプリンシパル単位の帰属、bedrock-mantleエンドポイントでのプロジェクト単位トラッキング、Anthropic Claude向けのワークスペース単位トラッキングといった複数の手段が並立していた。リクエスト単位の細粒度帰属はConverseおよびConverseStream APIではローンチ当初から提供されていたが、InvokeModel系には存在せず、SDKやAPIの選択がコスト配賦設計に影響していた。今回の拡張により、bedrock-runtimeエンドポイント全体で一貫したタグ運用が可能になる。
日本企業にとっての含意
複数事業部門が同一AWSアカウントでBedrockを共有する日本の大企業では、社内チャージバックや実験コストの可視化のために、アプリ側でリクエストIDに識別子を埋め込んだり、用途別にIAMロールを分けたりする運用が一般化していた。今後はメタデータフィールドに揃えることで、既存の自前実装を縮退できる。一方、落とし穴として、メタデータはモデル呼び出しログを有効化していないと取得できない点、およびログ送信先(S3/CloudWatch Logs)のストレージコストと保持ポリシーの再設計が必要になる点に注意したい。タグ命名規則をAWSのコスト配分タグと揃えておかないと、後段のFinOps集計で名寄せ作業が発生する。