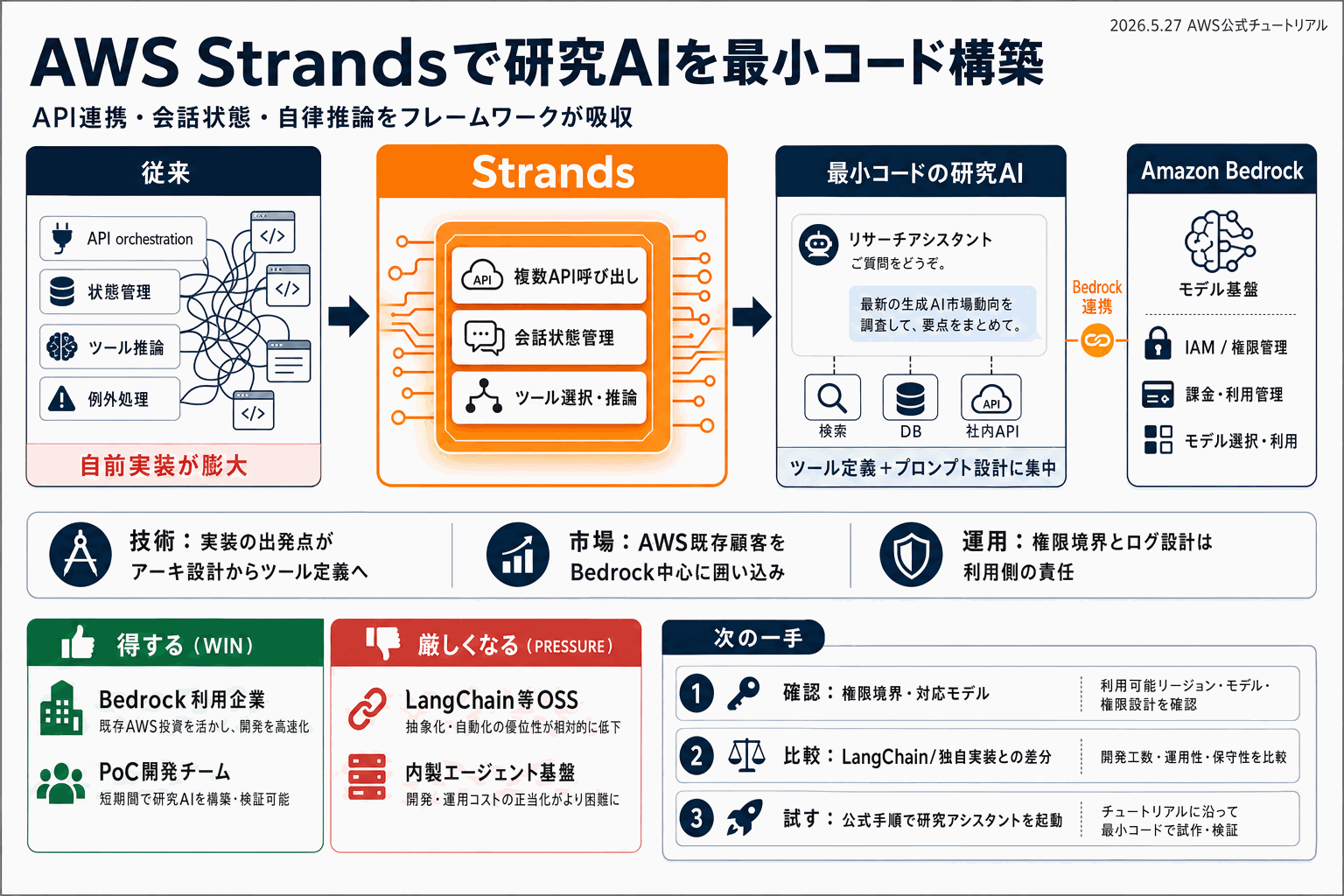
Strandsが解こうとしている課題
AWS Machine Learning Blogの今回の記事は、冒頭で「AIアプリを作るのにML博士号や数か月のアーキテクチャ格闘は不要なはず」と問題提起している。実際のエージェント実装では、複数API呼び出しのオーケストレーション、会話状態の保持、自律推論するエージェントの設計が絡み合い、シンプルなアイデアが大規模プロジェクトに膨張するという指摘だ。
Building an AI app shouldn't require a PhD in machine learning (ML) or months of wrestling with complex architectures.
Strandsは、この複雑性をフレームワーク側で抽象化し、開発者がツール定義とプロンプト設計に集中できるようにする位置づけで紹介されている。題材は調査支援アシスタント(research assistant)で、エージェントが情報源を自律的に呼び出して答えを組み立てるユースケースだ。
採用判断で押さえるべき論点
読者が判断すべきは「既存のLangChainや内製基盤からStrandsに乗り換える価値があるか」である。AWSスタックに既に深く根を張っているチームであれば、IAM・Bedrockモデル選択・CloudWatchログとの統合コストが下がる利点は大きい。逆にマルチクラウドやオンプレ要件があるチームは、フレームワークのロックイン度合いを実装前に確認したい。
落とし穴として、エージェントが外部APIを自律呼び出しする以上、ツールごとの権限境界・失敗時のリトライ・実行ログの監査要件は、フレームワークが解決してくれるものではない。本記事はあくまで「アプリを動かす最短経路」であり、本番運用の品質保証は読者側で別途設計する必要がある。まずは公式チュートリアル通りに動かし、自社ユースケースのツール群に置き換えたときの挙動差を観測することが現実的な第一歩になる。