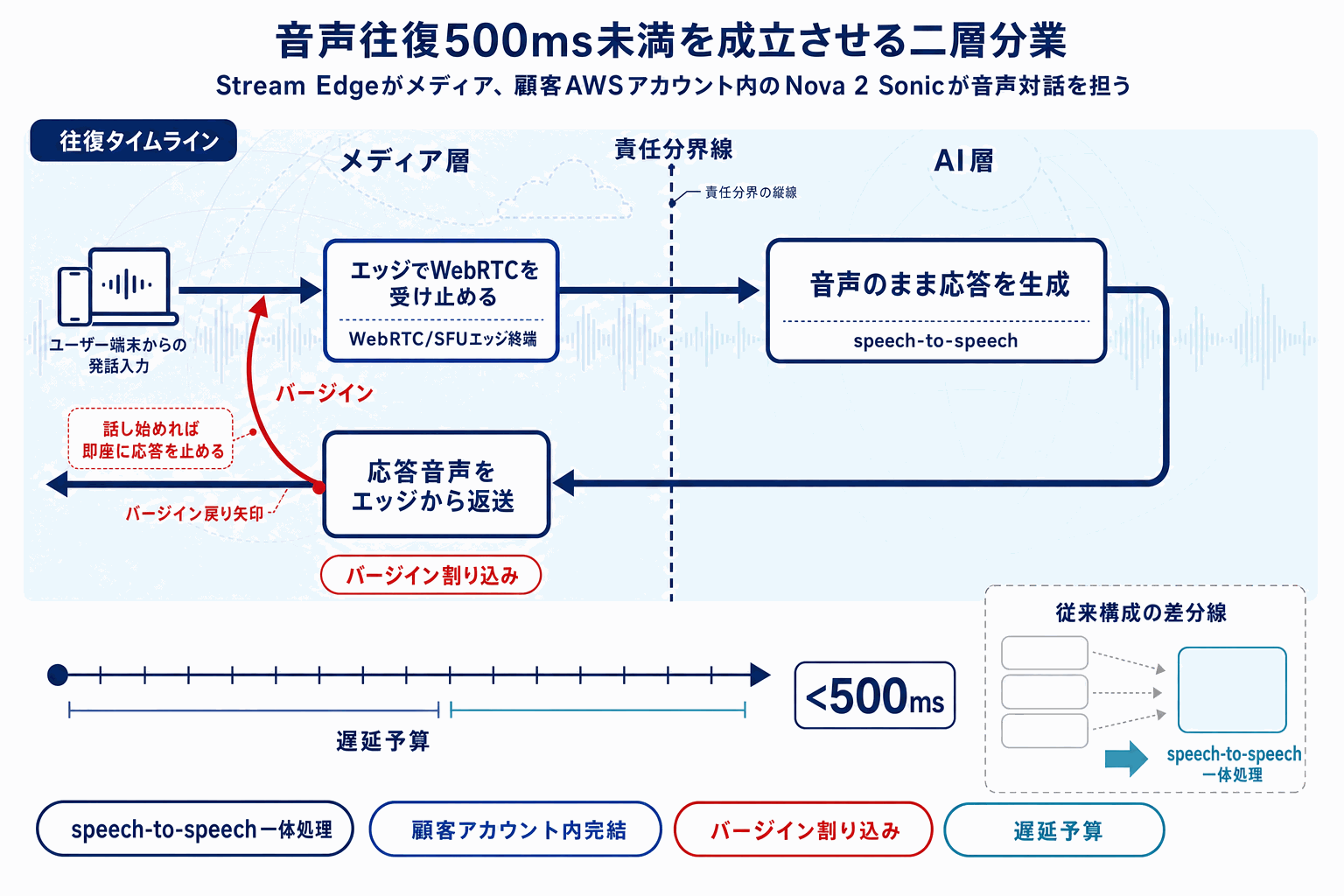
AWSは2026年5月16日付のMachine Learning Blogで、Stream Vision AgentsとAmazon Nova 2 Sonicを組み合わせたリアルタイム音声エージェントの構築手法を公開した。あわせてGetStreamが提供するVision AgentsのGitHubリポジトリも参照可能になっており、開発者はサンプル実装からすぐに着手できる構成になっている。
本記事の重要性は、AWS既存顧客にとって音声エージェントの選択肢が公式の参照実装として揃った点にある。これまでリアルタイム音声系のエージェント構築では、OpenAIのRealtime APIやGoogleのGemini Live系が先行していたが、Bedrock配下でNova 2 Sonicを音声基盤として、Stream側で映像・音声のストリーミング層を担う分業パターンが一次ソースとして整理された。マルチモーダルでの会話エージェントを社内に導入したい企業は、既存のAWS契約・IAM・データ所在地ポリシーをそのまま使える経路を一つ手に入れたことになる。
一方で、本ソースはあくまでAWS側の発信であり、レイテンシ実測値、対応リージョン、価格体系、商用利用時のSLAといった意思決定に直結する数値はブログ本文と公式ドキュメントで個別に確認する必要がある。日本市場での提供時期や東京リージョンでの利用可否も現時点のソースには明記されていない。
実装担当者はまずGitHubのVision Agentsリポジトリをcloneし、自社の定型音声ユースケース(コールセンター応答、議事録、店舗案内など)で応答遅延・認識精度・割り込み処理の挙動を測ることが現実的な次の一手となる。事業判断側は、既存音声AI基盤との比較軸を「AWS契約との一体運用」「データ越境」「課金単位」の3点で定義しておくと、PoCから本番移行の判断が早くなる。