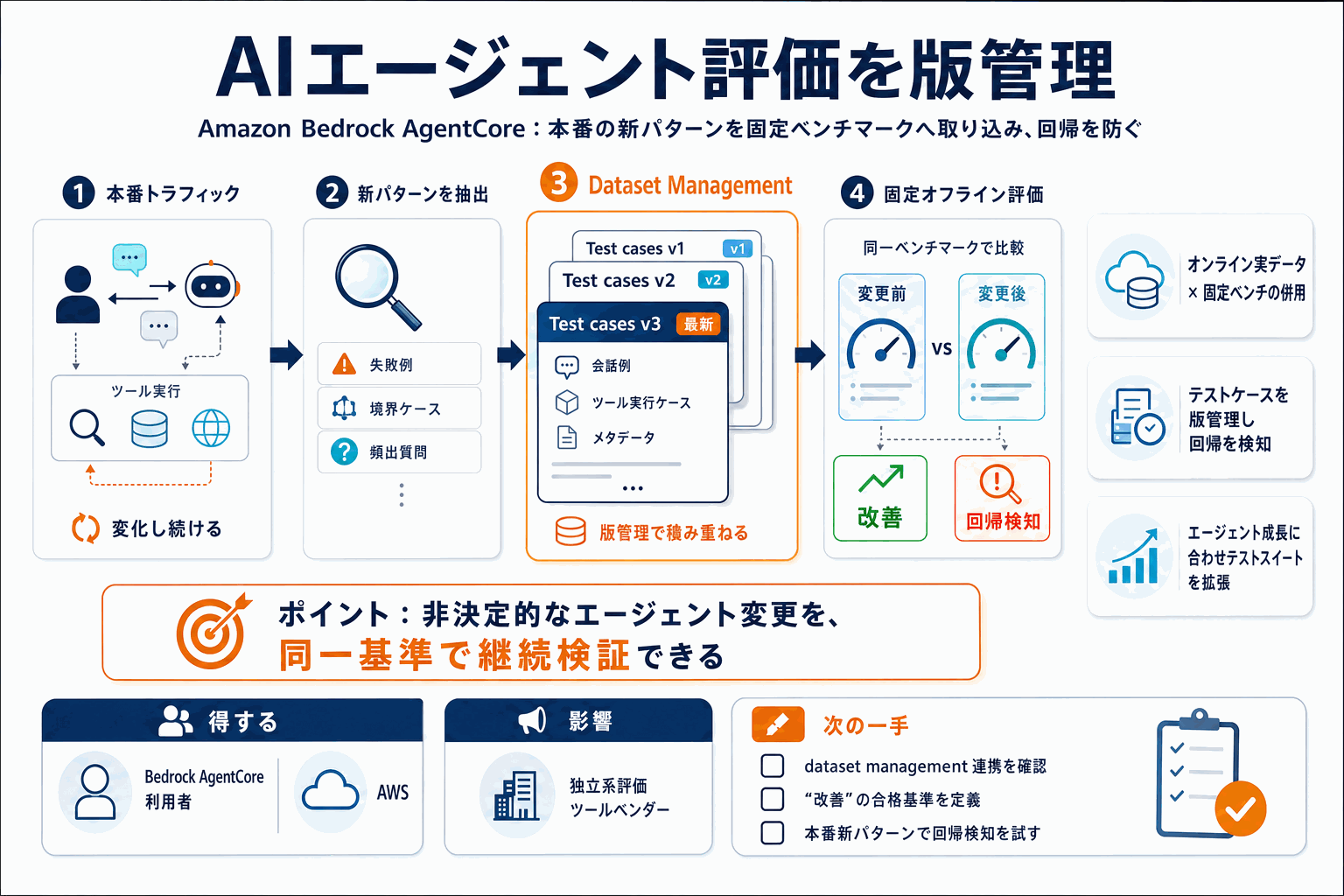
なぜ固定ベンチマークと実トラフィックを併用するのか
AWSは公式ブログで、Amazon Bedrock AgentCoreのdataset management機能を使い、エージェント評価用のテストケースを版管理されたデータセットとして扱う手法を提示した。ブログは評価の核心をこう説明する。
Agent evaluation is most powerful when you combine fast-moving online signals with stable offline baselines.
— AWS Machine Learning Blog
AIエージェントは本番で常に変化するトラフィックに晒される一方、改善を測るには動かない基準点が要る。速く動くオンラインのシグナルだけでは「本当に良くなったのか」を判定できない。固定したオフラインのベースラインを並走させることで、プロンプトやツール構成を変えた前後を同じ物差しで比較できる。
版管理されたテストフィクスチャという発想
注目すべきは、テストケースを「データセット」として版管理する点だ。ソフトウェア開発でテストフィクスチャをバージョン管理する規律を、エージェント評価に持ち込む。本番で発見した新しい失敗パターンをテストケースとして追加していけば、テストスイートはエージェントの成長に合わせて拡張される。一度直した不具合が再発していないかを、版を遡って検証できる。
非決定的な挙動を持つエージェントでは、同じ入力でも出力がぶれるため、回帰の検知が難しい。固定データセットで継続評価する仕組みは、この曖昧さを観測可能な数値に落とし込む土台になる。
着手時の落とし穴
落とし穴は、固定ベンチマークが古びることだ。本番トラフィックは変化し続けるため、初期に作ったテストケースだけを回し続けると、実運用の新しい課題を見逃す。本番から発見したパターンを継続的にデータセットへ取り込む運用を回さなければ、版管理の意味が薄れる。導入時は「誰が・いつテストケースを追加するか」の運用ルールを先に定義しておく必要がある。なお、本機能のコストに関する具体数値は公開記事には明示されていない。