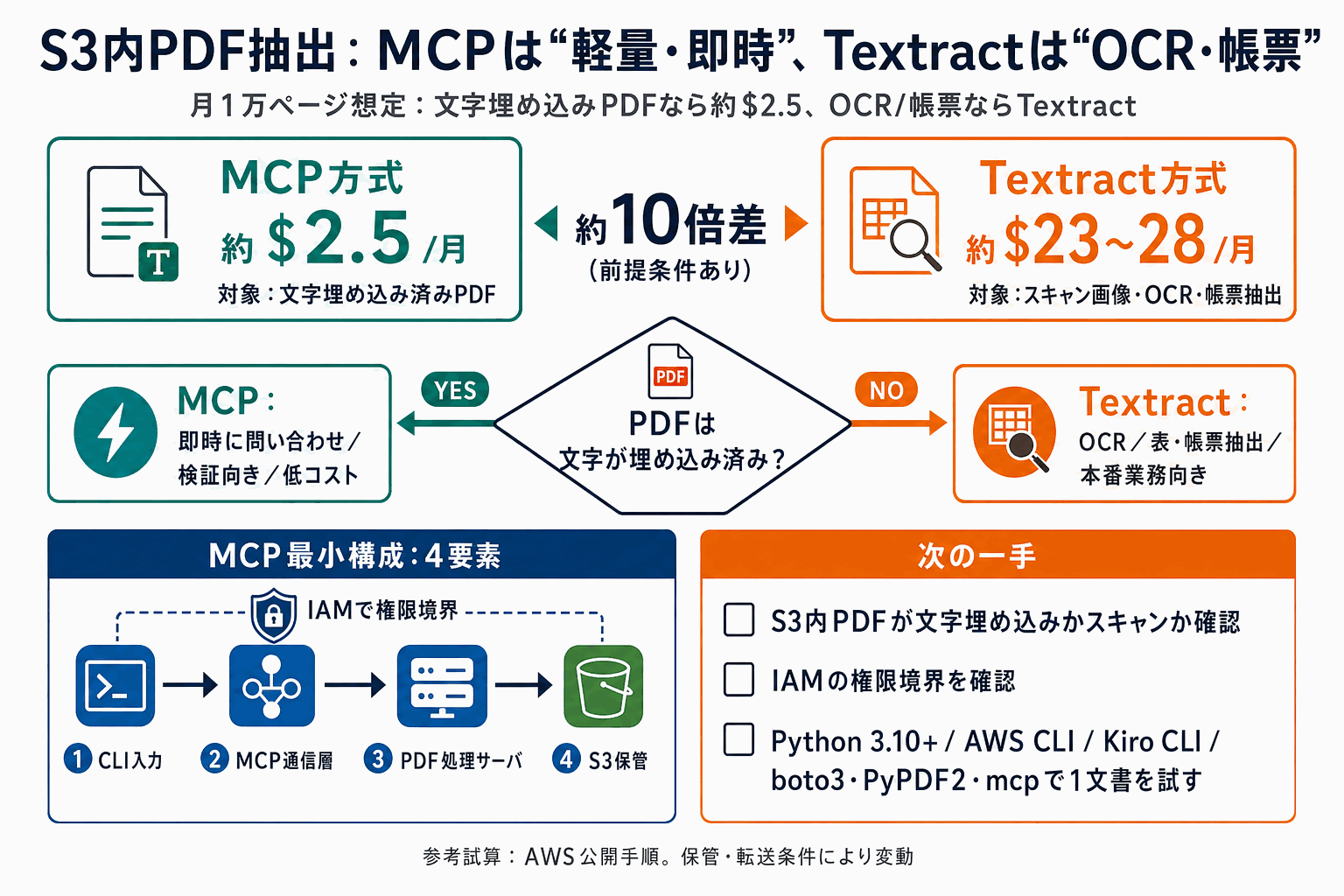
AWSが2026年6月26日、Amazon S3内のPDFからテキストをリアルタイムに抽出するサーバの構築手順を機械学習ブログで公開した。AIアプリと外部データを安全につなぐ共通規格MCP(モデルコンテキストプロトコル)を採用し、構成はコマンドライン入力・MCP通信層・PDF処理サーバ・S3保管の4要素で、権限はIAMで制御する。
判断材料はコストと用途の切り分けだ。月1万ページ想定でMCP方式は約2.5ドル、Amazon Textract方式は約23〜28ドルと試算される(参考値)。ただしMCP方式が成立するのは文字埋め込み済みPDFに限られ、スキャン画像の文字認識(OCR)や帳票・表の抽出が必要ならTextractを選ぶべきと明確に切り分けている。
前提はPython 3.10以降、AWS CLI、Kiro CLI、boto3/PyPDF2/mcpパッケージ。文書をすでにS3に貯め、バッチ完了を待たずに対話的アクセスを試したい事業者にとって、検証段階の低コスト選択肢として位置づく。