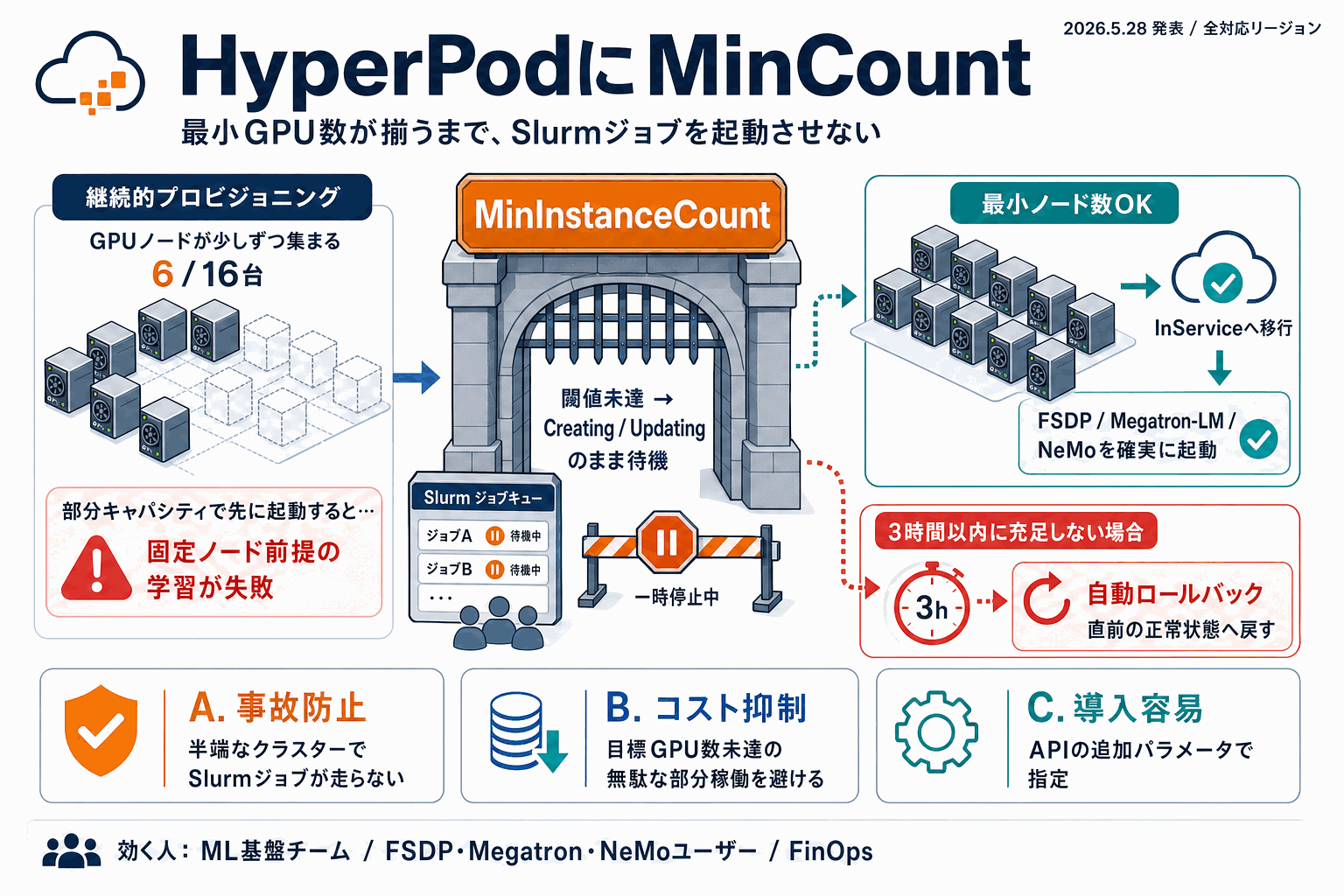
何が変わったか: 「部分起動」を明示的にゲートできるようになった
Amazon SageMaker HyperPodのSlurmクラスターは、継続的プロビジョニング(continuous provisioning)により利用可能な分から先にクラスターを立ち上げ、残りのインスタンスをバックグラウンドで非同期に追加する設計を採用している。起動は速いが、PyTorch FSDP・Megatron-LM・NVIDIA NeMo のように参加ノード数を固定して構成する分散学習では、部分キャパシティでInServiceに遷移するとジョブが効率的に動かない、あるいは正しく起動しないという課題があった。
今回追加された MinCount(API上は `MinInstanceCount`)は、この設計上のトレードオフに明示的なガードを挟む。
MinCount lets you specify the minimum number of instances that must be successfully provisioned before an instance group transitions to InService status
閾値が満たされるまでインスタンスグループは Creating または Updating のままで、Slurmジョブのスケジューリングは始まらない。閾値到達後にInServiceへ移り、HyperPodはターゲット台数までインスタンス追加を継続する。
落とし穴: 3時間ロールバックの挙動を運用に織り込む
見落としやすいのが安全装置の振る舞いだ。MinCountが3時間以内に満たされない場合、システムは自動的に直前の正常状態にロールバックする。つまり「容量が取れないままクラスターを掴み続ける」状態を回避できる反面、ジョブ投入のリトライ戦略とアラート設計は明示的に組み直す必要がある。
他社事例との比較で見ると、自前でSlurm起動前にノード数をチェックするスクリプトを差し込んでいたチームや、Terraform/CDK側でカスタムの待機ロジックを書いていたチームは、その層を基盤側に寄せられる。一方で、ロールバック発生時にどのアラートをどこに飛ばすか、再投入を自動化するか手動承認にするかは、MinCount自体には含まれない設計判断として残る。
コスト面の公開数値はないが、定性的には「目標GPU数に満たないまま部分稼働で課金される」リスクと、「ロールバックで一旦解放してから再取得する」リスクのどちらを取るかを、SLAとコスト効率の優先度に沿って宣言できるようになった点が実装判断を変える。HyperPodがサポートされる全AWSリージョンで即時利用可能で、既存の `CreateCluster`/`UpdateCluster` 呼び出しに引数を1つ足すだけで導入できる。