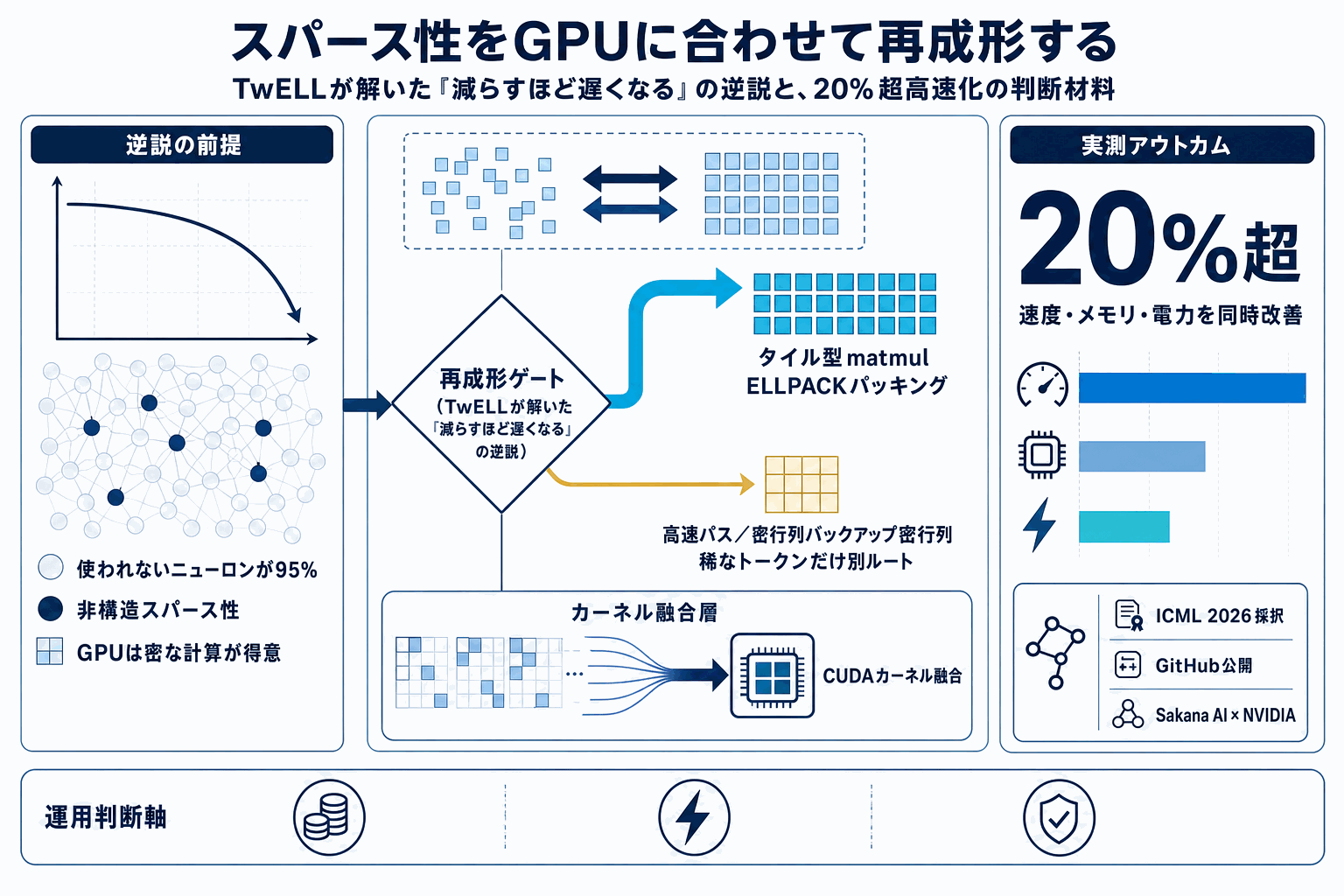
Sakana AIが2026年5月9日に公開した「Sparser, Faster, Lighter Transformer Language Models」は、Transformer型言語モデルを疎化し、推論をより速く・より軽くするための研究をまとめたものだ。同社サイトの解説ページ、arXivの論文、GitHubの実装リポジトリ『SakanaAI/sparser-faster-llms』が同じタイミングで公開されており、読者は概念解説から実装コードまで一次ソースだけで辿れる。
この公開形態は、評価の出発点として重要だ。論文単独では再現性に疑問が残り、コード単独では設計意図が読み取りにくい。両者が揃うことで、ベースラインの条件、対象モデルサイズ、評価指標を読み手が確認したうえで自社ワークロードに当てはめる議論ができる。推論コスト削減を狙う事業者にとっては、海外発の効率化研究と並べる比較対象が一つ増えた格好になる。
読者の動き方としては、まず解説ページとarXiv本文で「どのアーキテクチャに、どの程度の疎化を、どの評価条件で適用したのか」を押さえることが先になる。そのうえでGitHubリポジトリを取得し、自社の代表的な推論ワークロードでレイテンシ・スループット・メモリを測ることで、現行スタックとの差分が定量化できる。逆に、ベンチマーク条件と自社ワークロードのギャップを切り分けないまま採否を判断すると、論文上の改善幅と本番環境の改善幅がずれる可能性が高い。
国内開発現場にとっての意味は、効率化系の研究で「日本発・一次ソース・コード付き」という選択肢が増えた点にある。海外論文の追試と異なり、文脈を共有しやすい一次情報として扱える。