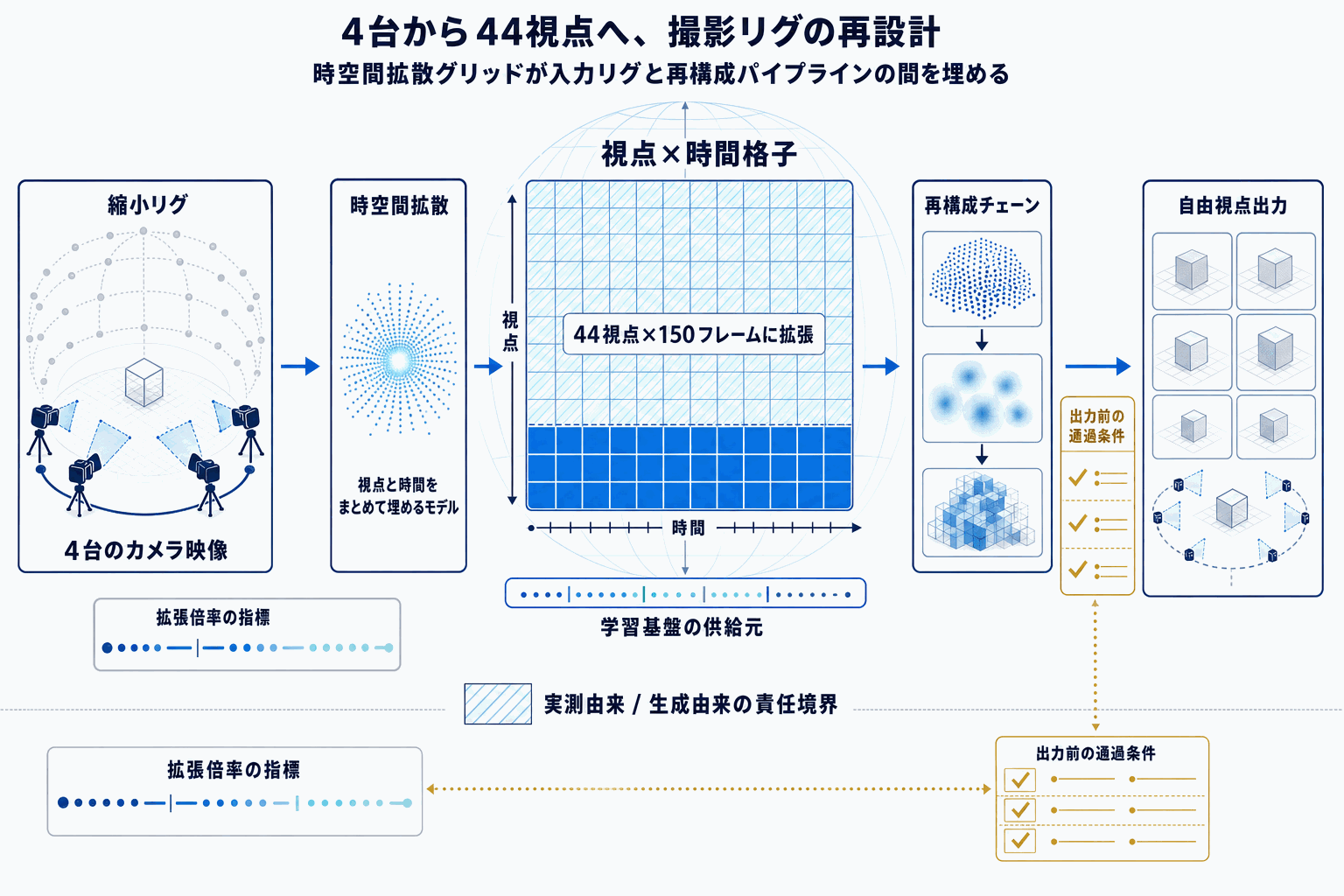
Diffuman4Dは、浙江大学の3Dビジョン研究グループ(zju3dv)が公開した、疎な多視点動画入力から高忠実度な4D人物レンダリングを行う手法である。今回確認できる一次情報は、GitHubリポジトリ(zju3dv/Diffuman4D)、論文(arXiv:2507.13344)、学習済みモデル(krahets/Diffuman4D)、再アノテーション済みDNA-Renderingデータセット、サンプルテストデータの5点で、いずれもHugging Faceまたは標準的な研究公開チャネルに置かれている。
注目すべきは、コード単独ではなく学習済み重みと前処理済みデータセット、さらに動作確認用のサンプルデータまでが同時に揃っている点である。4D人物レンダリング系の研究は、データセットの前処理(カメラキャリブレーション、マスク、SMPL系のフィッティングなど)が再現の最大の障壁になりやすい。再アノテーション済みのDNA-Renderingが配布されることで、前処理パイプラインの再構築なしに学習・評価の入口に立てる構成になっている。
読者の意思決定の観点では、まずライセンスと利用条件の確認が出発点になる。DNA-Renderingは元データセット側の規約があるため、再配布版を商用検討に使う前に二重に読み合わせる必要がある。次に、サンプルテストデータでの推論を実際に回し、出力品質・所要VRAM・処理時間を自社のカメラ構成と突き合わせて測ることで、自由視点映像やボリュメトリックキャプチャの内製・外製判断の比較基準として機能させられる。