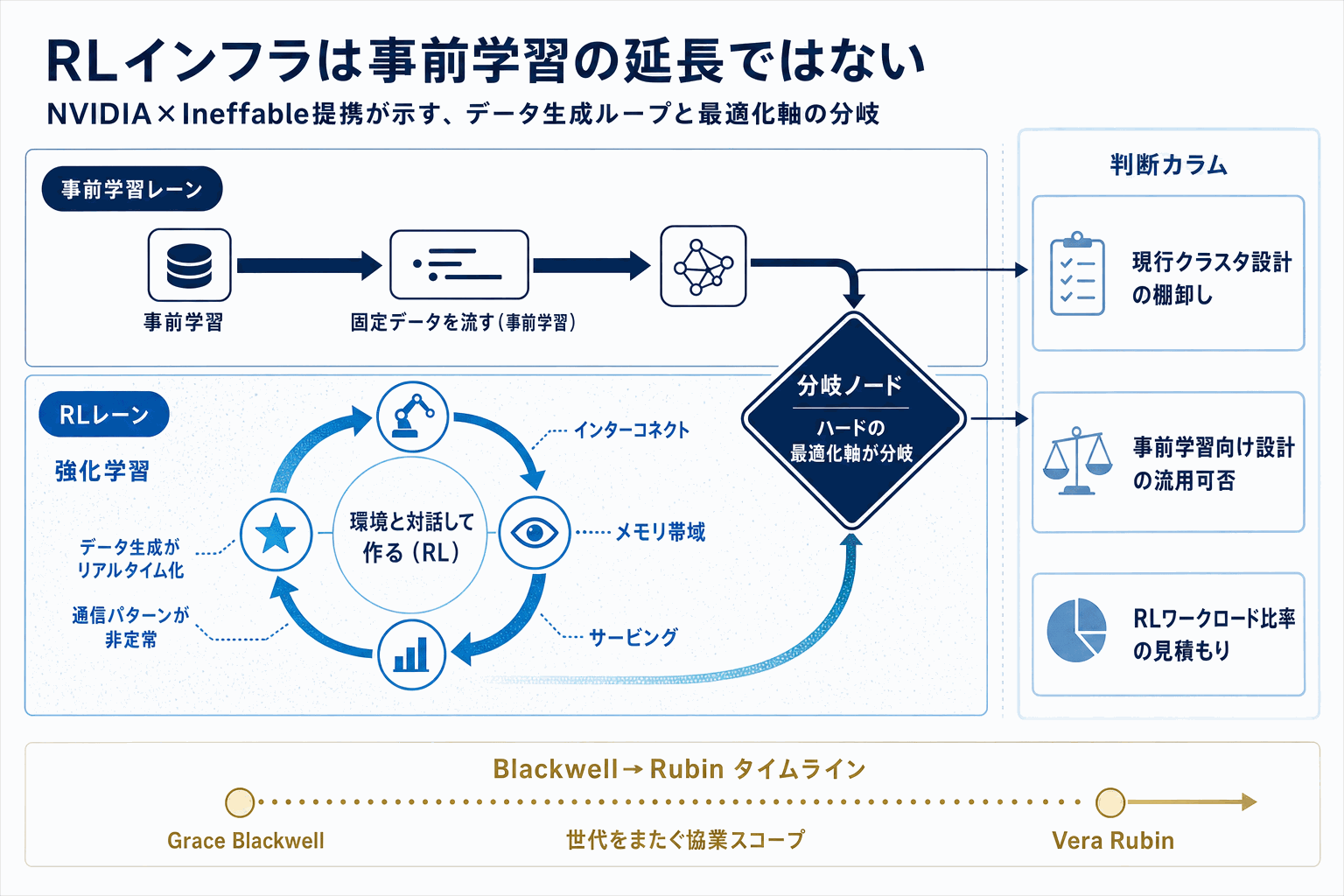
NVIDIAは2026年5月13日付の公式ブログで、Ineffable Intelligenceとの提携により強化学習(RL)インフラを共同構築すると発表した。RLは事前学習を終えたモデルを目的特化に磨き込むポストトレーニングの中核手法で、ChatGPT以降の対話モデル品質を押し上げてきた本丸の領域にあたる。
RLワークロードは事前学習と性質が大きく異なる。モデルが環境や評価器とやり取りしながら推論(ロールアウト)を回し、その結果を使って学習を進めるため、推論側と学習側のGPUが交互にビジー状態になり、従来の事前学習クラスタ設計のままでは利用率が落ちやすい。報酬モデル、リファレンスモデル、ポリシーモデルが同時に乗る構成も多く、メモリ配置とスケジューリングの難度が高い。
NVIDIAが専業企業と組んでこの層に踏み込む意味は、事前学習向けに整備したGPU基盤を、ポストトレーニング層にもリファレンス構成として横展開する点にある。OpenAIやAnthropicが内製で築いてきたRLスタックに対し、外販可能な共通インフラの選択肢が立ち上がる構図となる。
日本の開発現場への直接影響は段階的だが、独自LLMをRLで磨き込むフェーズに入ったチームにとっては、GPU調達と同時にRLツールチェーンを評価対象に含める判断材料が増える。逆にRLステージを外注で済ませる戦略を取る企業は、内製/外注の境界線を改めて引き直す局面になる。本発表時点では具体的な製品名・提供時期・価格の詳細はNVIDIAブログ本文に依存するため、導入検討時は一次情報での仕様確認が前提となる。