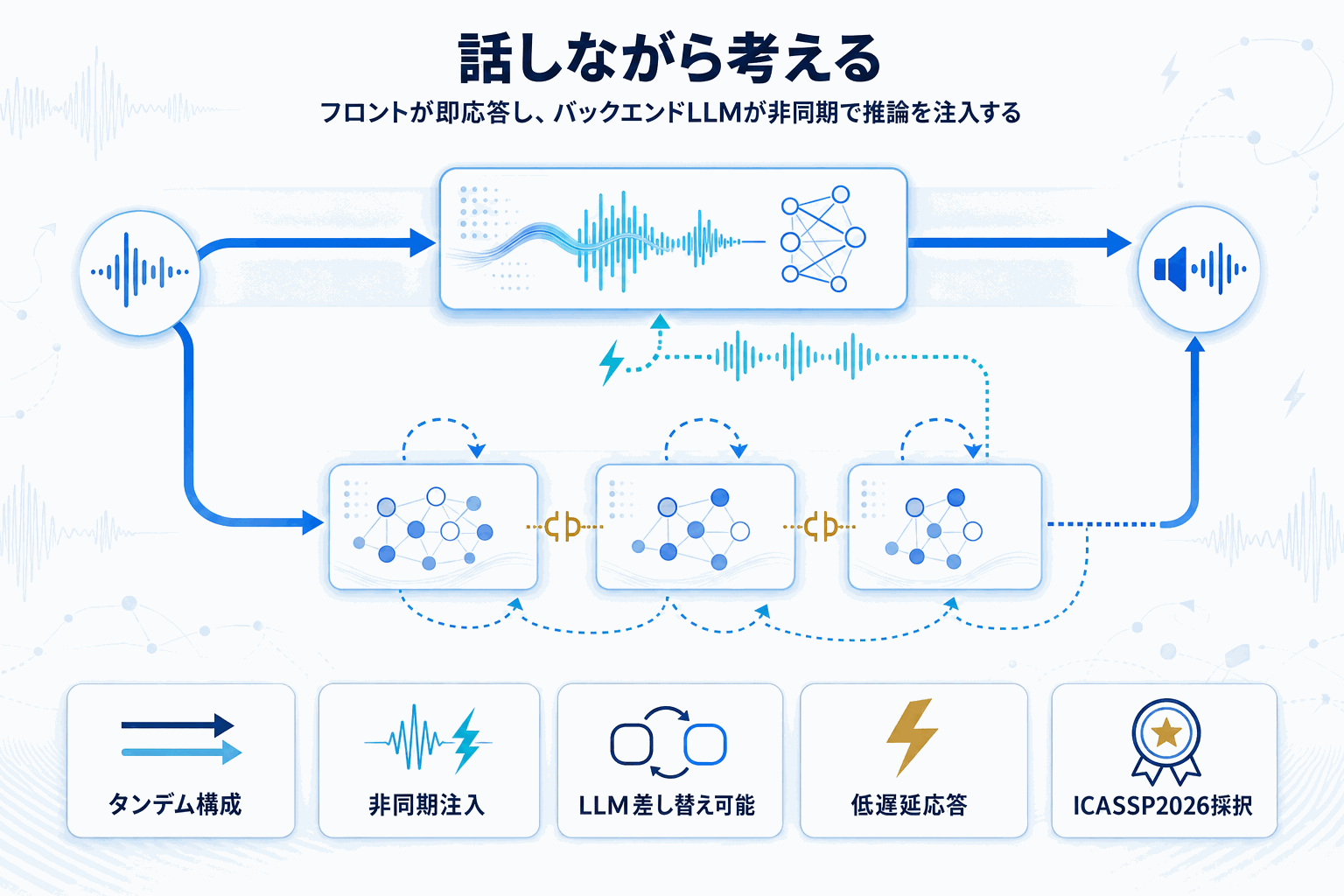
Sakana AIが2026年4月29日に公開した「KAME」は、リアルタイム音声対話AIにおける長年のジレンマに正面から取り組んだアーキテクチャだ。従来、音声AIには2つの主流アプローチがあった。ひとつは応答が速いSpeech-to-Speechモデルだが、推論は浅くなりがち。もうひとつはLLMをカスケード接続する方式で、賢いが遅延が発生し会話のテンポが崩れる。
KAME(日本語の「亀」に由来)は、この二択を並列化で解く。フロントのSpeech-to-Speechモデルが即座に発話を開始し、同時にバックエンドのLLMが非同期で応答候補を生成。生成結果は「オラクル信号」としてリアルタイムにフロントへ注入される。結果として「考えてから話す」ではなく「話しながら考える」パラダイムが実現する、というのが論文の主張だ。
実装面で注目すべきは、バックエンドLLMが完全に差し替え可能である点。GPT-4.1、Claude Opus、Gemini 2.5 Flashなどをタスクに応じて選択でき、フロント側の再学習や改修は不要となる。Sakana AIの実験では、Claudeが推論系タスク、GPTが人文系タスクでそれぞれ高スコアを記録する傾向が観察されたという。これはタスク別のバックエンド選定指針として、音声プロダクト開発者に直接参考になる。
本研究はICASSP2026に採択済みで、モデルはHugging Face(SakanaAI/kame)で公開、論文はarXivで閲覧できる。コールセンター、車載アシスタント、音声エージェントなど、応答速度と回答品質の両方が業務KPIに直結する領域での検証に使える素材が揃った形だ。日本発の音声AI研究が国際会議で採択され、同時にオープンに公開される流れは、国内の音声UI開発者にとって即座に手を動かせる機会となる。