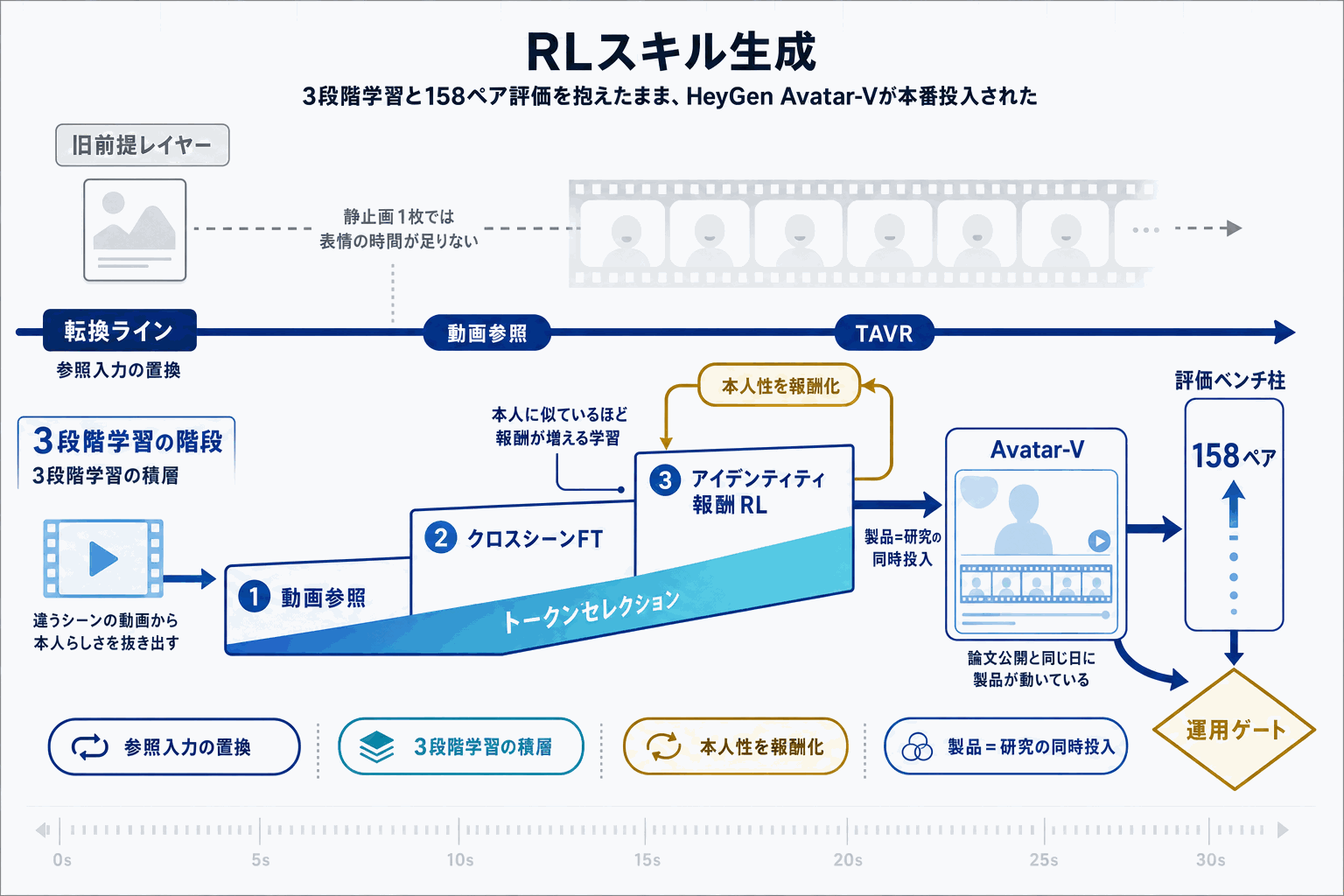
HeyGen Researchが、動画を参照入力としてトーキングアバターを生成するフレームワーク『TAVR(Talking Avatar generation from Video Reference)』をarXivで公開した。従来のトーキングアバター生成は、生成対象と同一シーン内の静止画を参照条件とする画像→動画パイプラインが主流だったが、単一視点の静止画では時間的・表情的な手がかりが不足し、カスタム背景での高忠実度生成に限界があった。TAVRはこの前提をクロスシーンの動画入力に置き換える。
技術的な構成は、長い時間コンテキストの処理とクロスシーン間のドメインギャップを橋渡しするトークンセレクションモジュールと、3段階の学習スキームで成り立つ。まず同一シーン動画で外見コピーの基盤を事前学習し、次にクロスシーン参照でファインチューニングして異シーン適応を獲得、最後にアイデンティティ類似度を報酬とする強化学習で本人性を最大化する。
評価面では、クロスシーンの頑健性を体系的に測るため、158ペアのクロスシーン動画ペアからなる新ベンチマークを構築・公開した。論文では、TAVRが推論時の柔軟な動画参照から恩恵を受け、既存ベースラインを定量・定性の双方で一貫して上回ったと報告している。
注目すべきは、本研究が既にHeyGenの本番環境にデプロイ済みで、HeyGen Avatar-Vとして製品化されている点である。論文公開と商用投入が同時であり、研究成果がただちにユーザーの手元で動く段階に入った。AIアバター・バーチャルプレゼンター分野では、静止画参照を前提としたサービスとの差別化軸が、動画参照という具体的な入力仕様で示されたことになる。肖像権・同意取得・なりすまし対策といった運用論点は、技術の実用化と同じ粒度で各社が整備する段階に移る。