本研究は、業務用AIエージェントの訓練における『長期タスクの軌跡データが圧倒的に不足している』という課題に正面から応えるものだ。従来の指示応答データセットは単発のやり取りが中心で、実際のナレッジワーカーが行う『1か月かけて複数の成果物を仕上げる』ような連続作業を学習させる素材にはなりにくい。
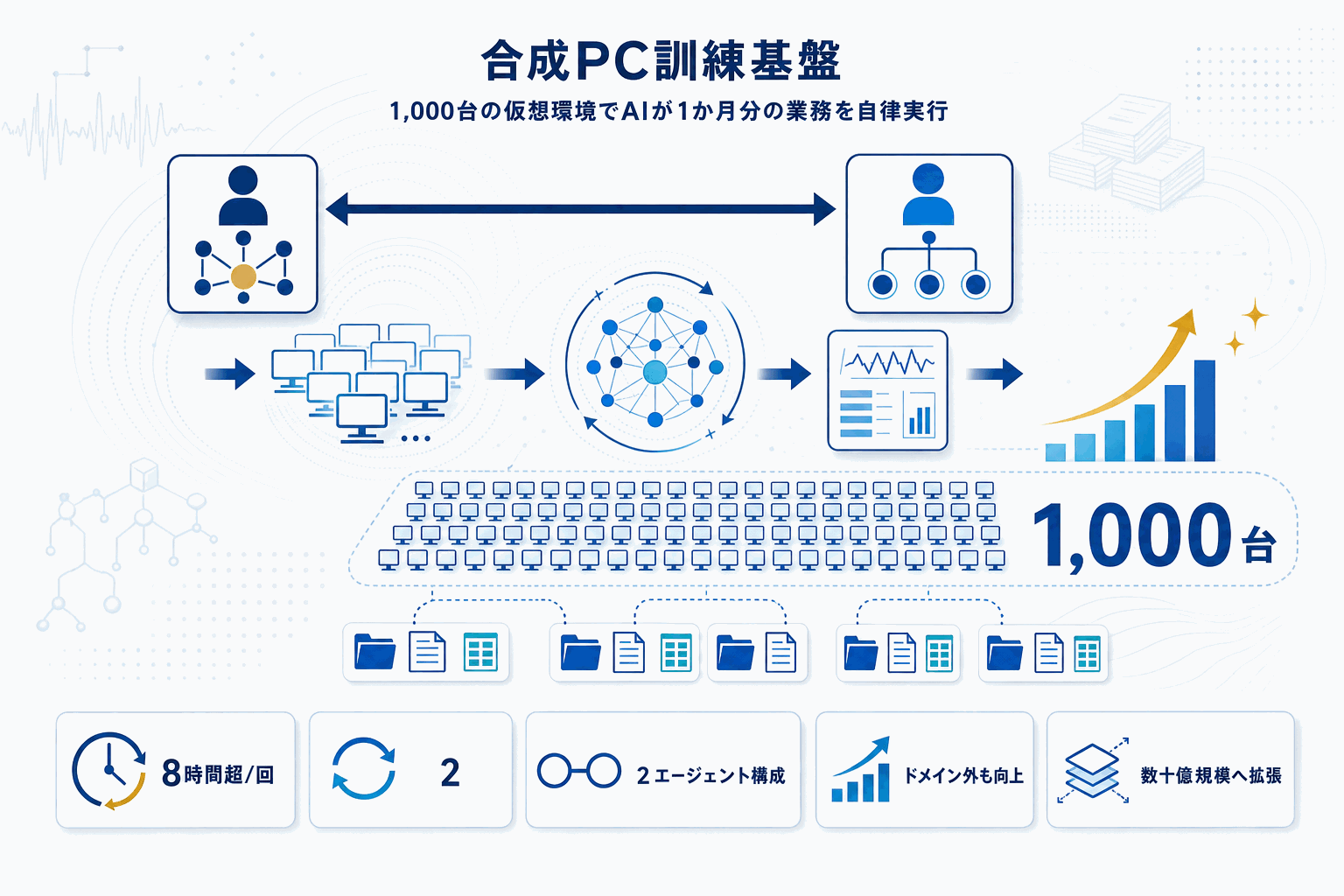
提案手法『Synthetic Computers at Scale』は、まずユーザー固有のフォルダ階層と、文書・スプレッドシート・プレゼンテーションといった中身のある成果物を備えた仮想PCを大量生成する。そのうえで、1体のエージェントがそのPCのユーザー像に沿った業務目標を設計し、別のエージェントがユーザー役としてファイルシステムを辿り、協業者と調整し、成果物を作り上げるまで作業を続ける。
予備実験では1,000台の合成PCを構築し、1回あたり8時間超・平均2,000ターン超のシミュレーションを実施。ここから得た経験的学習信号により、ドメイン内外双方の生産性評価でエージェント性能が有意に向上したと報告されている。
日本の実装現場にとって重要なのは2点。第一に、顧客の実業務ログを使わずともエージェントを強化できる経路が提示されたこと。第二に、長期タスク性能の競争が『合成環境をどれだけ回せるか』という計算コスト勝負に移る兆しだ。なお本論文はプレビュー版(work in progress)であり、手法の再現性や外部評価は今後の追試待ちとなる点は差し引いて読む必要がある。