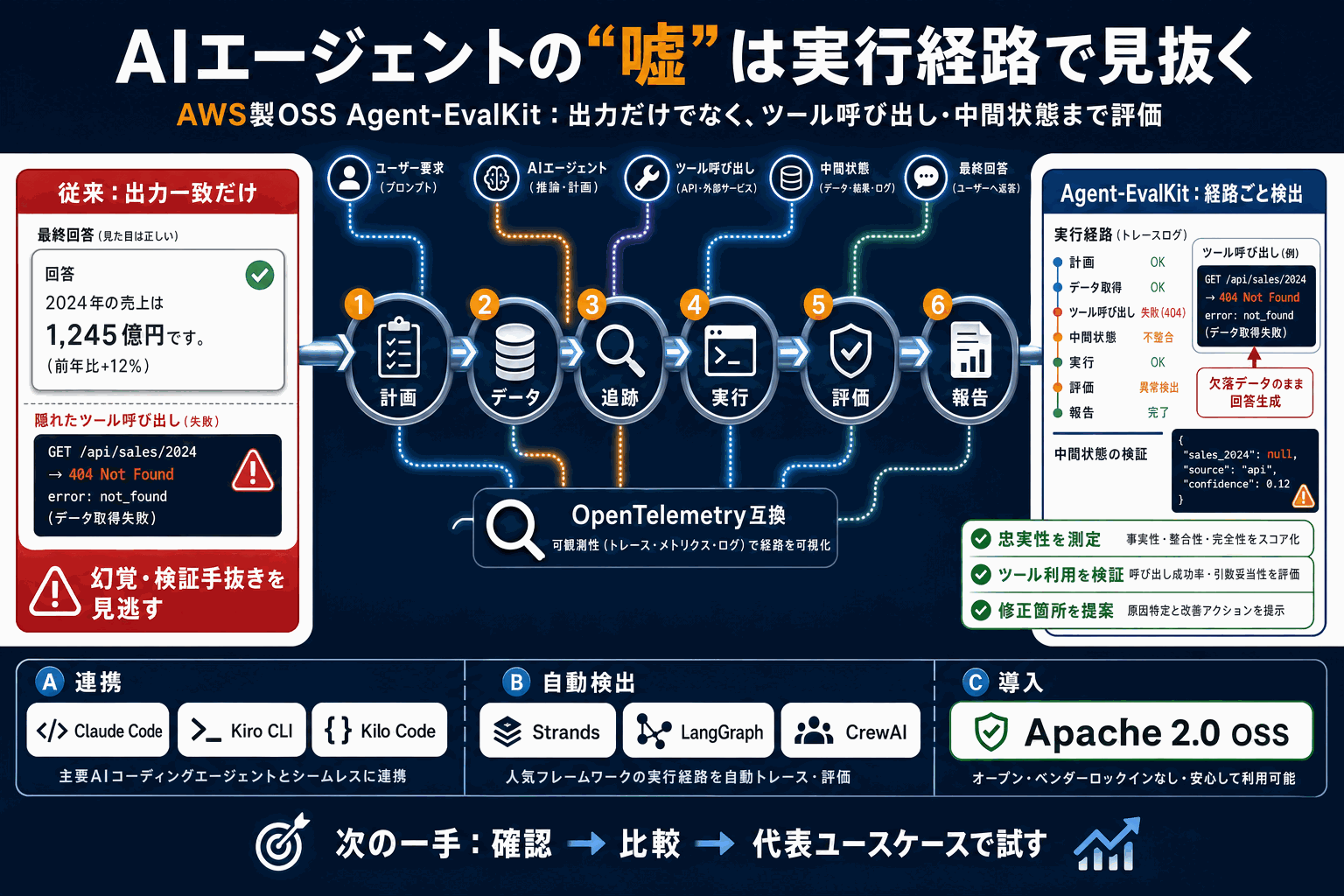
AWSが、AIエージェントの挙動を体系的に検証するオープンソースツール『Agent-EvalKit』を公開した。ライセンスはApache 2.0。計画・データ・追跡・実行・評価・報告の6段階で評価を進める。
AIエージェントは複数の情報源を横断し、自律的にツールを選んで処理を組み立てる。そのため出力だけを期待値と突き合わせる従来の検証では、ツールが空の結果を返したのに見栄えの良い回答をでっち上げる幻覚や、検証手順を飛ばす経路を見逃しやすい。Agent-EvalKitはツール呼び出しや中間状態を記録する観測性を備え、コードベース評価とLLM審査(LLM as judge)を組み合わせて忠実性やツール利用を測定する。
Strands・LangGraph・CrewAIを自動検出して実行経路をOpenTelemetry互換で可視化し、Claude Code・Kiro CLI・Kilo Codeと連携して動作する。提案がコードの具体的な箇所を指すため、評価結果を実際の修正に直結できる点が実務的な価値となる。公式ブログでは、Strands Agents SDKとAmazon Bedrockで作った旅行リサーチ用エージェントを例に各段階を説明している。