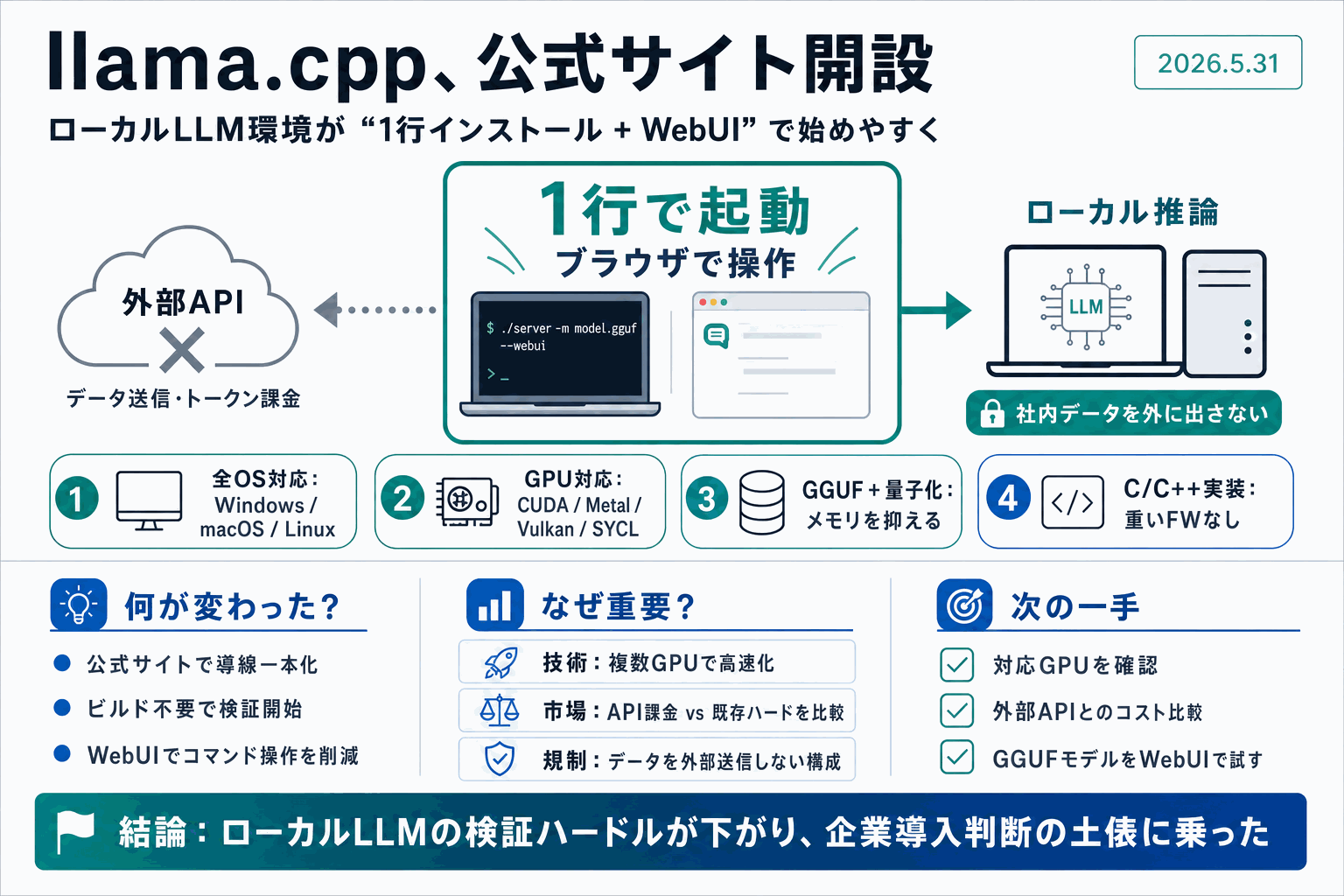
llama.cppの中心開発者Georgi Gerganov(ggerganov)氏が、同プロジェクト初の公式ウェブサイトを開設し、トップページにOSをまたいで使える1行のクロスプラットフォーム・インストーラを公開した。本人の投稿は狙いを「local AI(手元のPCでAIを動かすこと)を誰もが使える状態にする」ことだと説明している。
llama.cppはC/C++で書かれたLLM推論基盤で、GGUF形式のモデルをローカルで動かす事実上の標準である。これまで導入はOSごとにビルド手順とインストール手順を読み分ける必要があった。1行インストーラはこのOS差を1つのコマンドに吸収し、検証環境の立ち上げを手作業のビルドから単一コマンドへ短縮する。
プロジェクトでは並行して、下流利用者向けの配布パッケージ改善の議論(Discussion #15313)や、AMD Ryzen AIプラットフォームのNPU公式対応の要望(Issue #14377)も公開されている。導入の簡便化と対応ハードの拡張が同時に進めば、クラウドに依存せず手元でモデルを動かす選択肢の裾野が直接広がる。