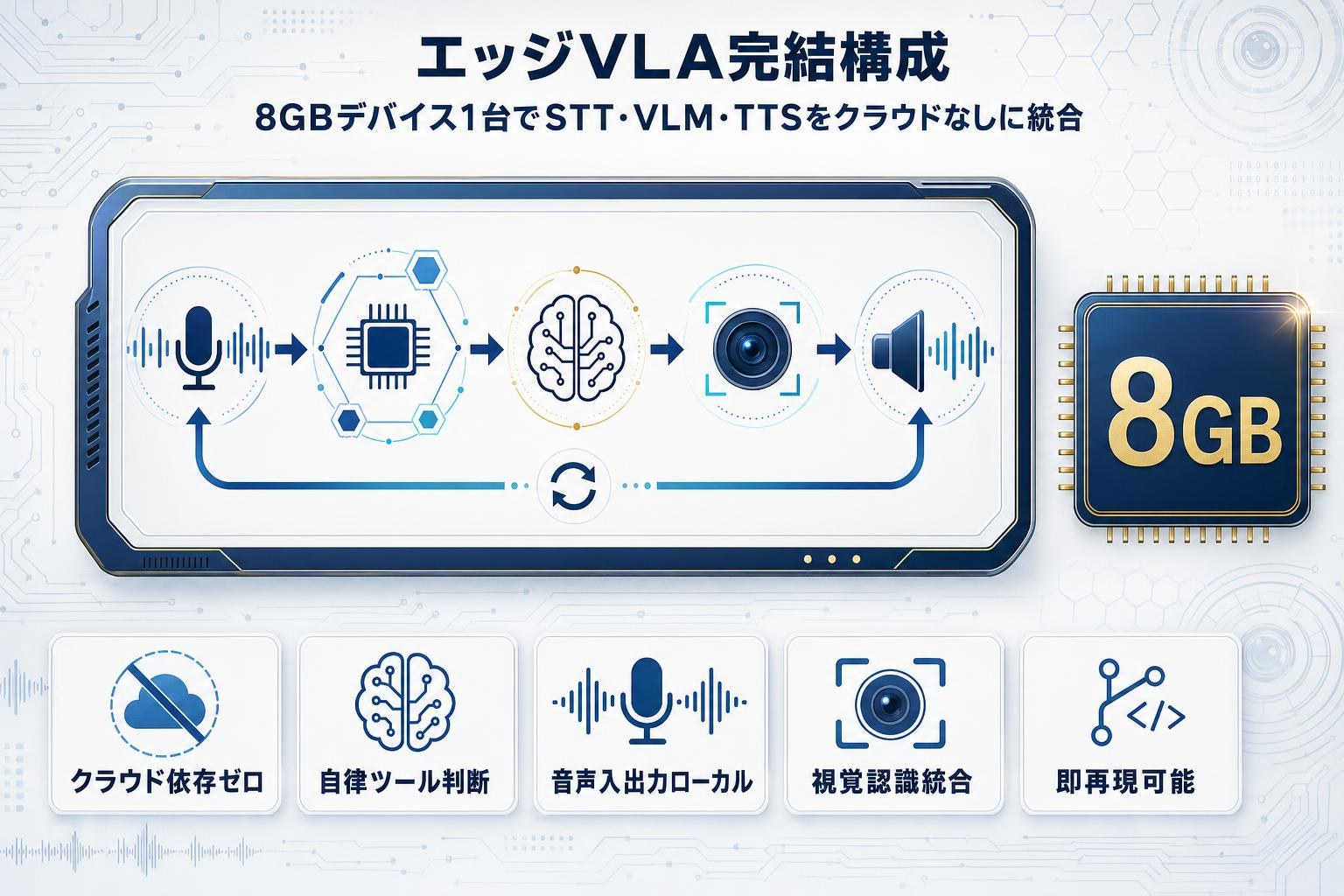
今回公開されたデモは、Jetson Orin Nano Super(8GB)という限られたメモリのエッジデバイス上で、Gemma 4 E2BのQ4_K_M量子化版(GGUF形式)をllama-serverで提供し、音声認識にParakeet STT、音声合成にKokoro TTSを組み合わせ、すべての処理をローカルで完結させた構成である。
技術的な注目点は3つある。第一に、llama-serverを--jinjaフラグ付きで起動することでGemma 4のネイティブツールコール機能を有効化し、モデルに公開するツールを「look_and_answer」1つだけに絞った点。これによりモデル自身が「カメラを見るべきか」を判断する自律的な動作を、最小の設計で実現している。第二に、-ngl 99で全レイヤーをGPUにオフロードし、8GB枠に量子化モデルとマルチモーダルパイプラインを収めた構成が、VRAM制約下の実装の具体解を示している点。第三に、STT・LLM・TTSをすべてオンデバイスで完結させたため、ネットワーク断やデータ持ち出し制約のある環境でも動作する。
読者にとっての意味は、クラウドAPIを前提としないマルチモーダルAIエージェントの実装パターンが、市販のJetsonハードとオープンモデル、OSSの組み合わせで成立することが示された点にある。実装コードはGitHubのGoogle_Gemmaリポジトリ(Gemma4_vla.py)として公開されており、ロボティクスや組み込み向けPoCの出発点としてそのまま参照できる。