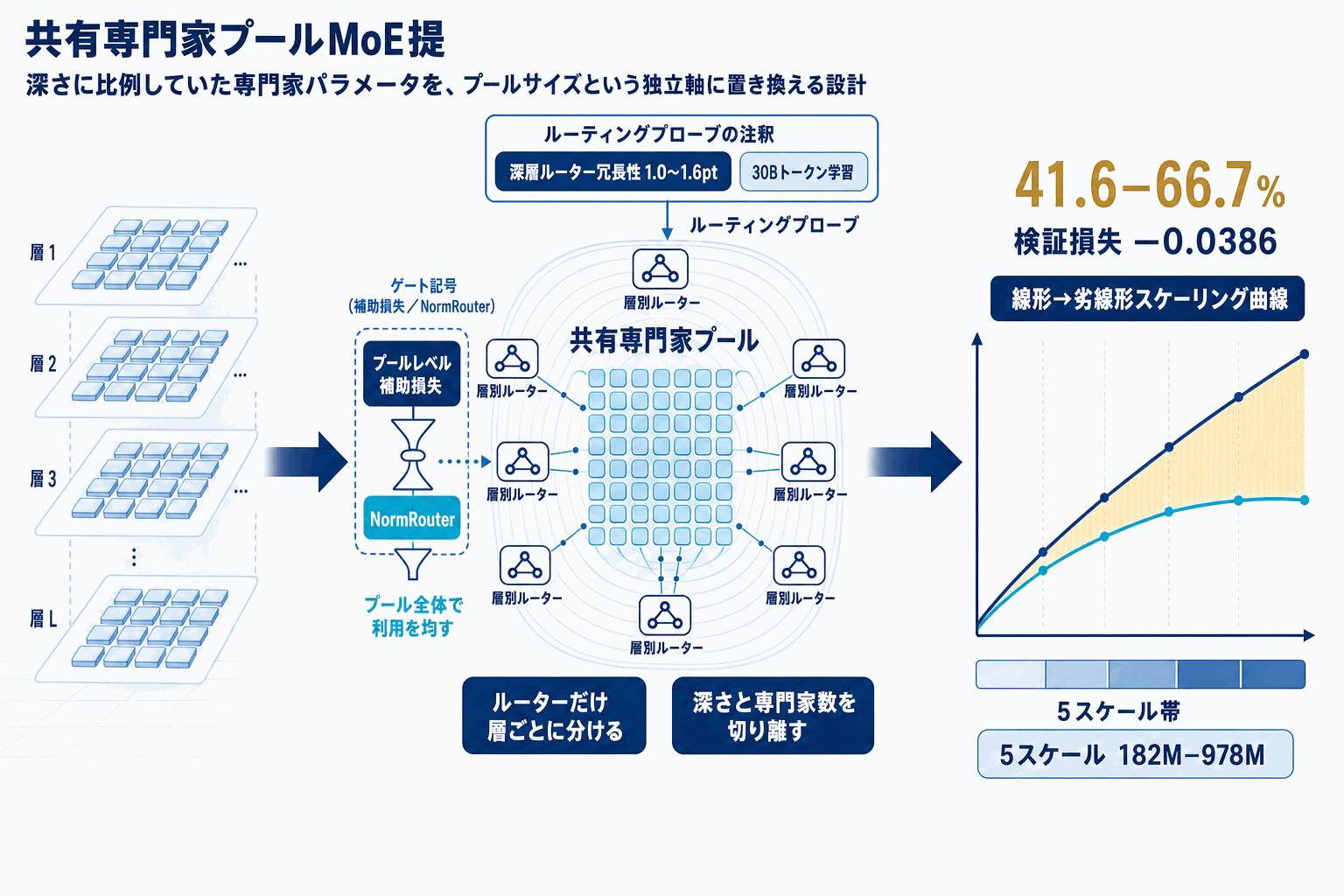
UniPoolは、Mixture-of-Experts(MoE)アーキテクチャが抱えていた「レイヤーごとに独立した専門家集合を持つ」という暗黙の前提に正面から疑問を投げかける研究である。著者らはまず、ルーティングプローブと呼ぶ実験で、学習済みMoEモデルの深いレイヤーのtop-kルーターを一様ランダムルーティングに置き換えても下流精度の低下が1.0〜1.6ポイントに留まることを観測した。これは、深層の専門家容量に相当量の冗長性があることを示す結果で、「各レイヤーが専用の専門家を持つ必要はない」という仮説の根拠となっている。
この観察を踏まえ、UniPoolは全レイヤーが単一の共有専門家プールを参照し、ルーターだけをレイヤーごとに独立させる設計を採る。共有化に伴う学習の不安定性・利用偏りに対しては、プール全体で専門家利用バランスを保つプールレベル補助損失と、スパースかつスケール安定なルーティングを行うNormRouterという2つの仕組みを導入した。
評価はLLaMA系の182M、469M、650M、830M、978Mという5スケールのモデルをPileから30Bトークンで学習する形で行われ、すべてのスケールで一致条件のバニラMoEに対して検証損失とperplexityを一貫して改善し、最大で検証損失0.0386の低減を記録した。さらに、専門家パラメータ予算を41.6〜66.7%まで削減した縮小プール版でも、テスト範囲のスケールでバニラMoEと同等以上の性能を達成している。
実務上の含意は明確で、これまでレイヤー数に線形で増えていた専門家パラメータを劣線形に抑える設計指針が一次情報として提示された意味は大きい。読者は自身のMoE検証環境でルーティングプローブを再現し、プールサイズを深さから切り離したハイパーパラメータとして測定する価値がある。