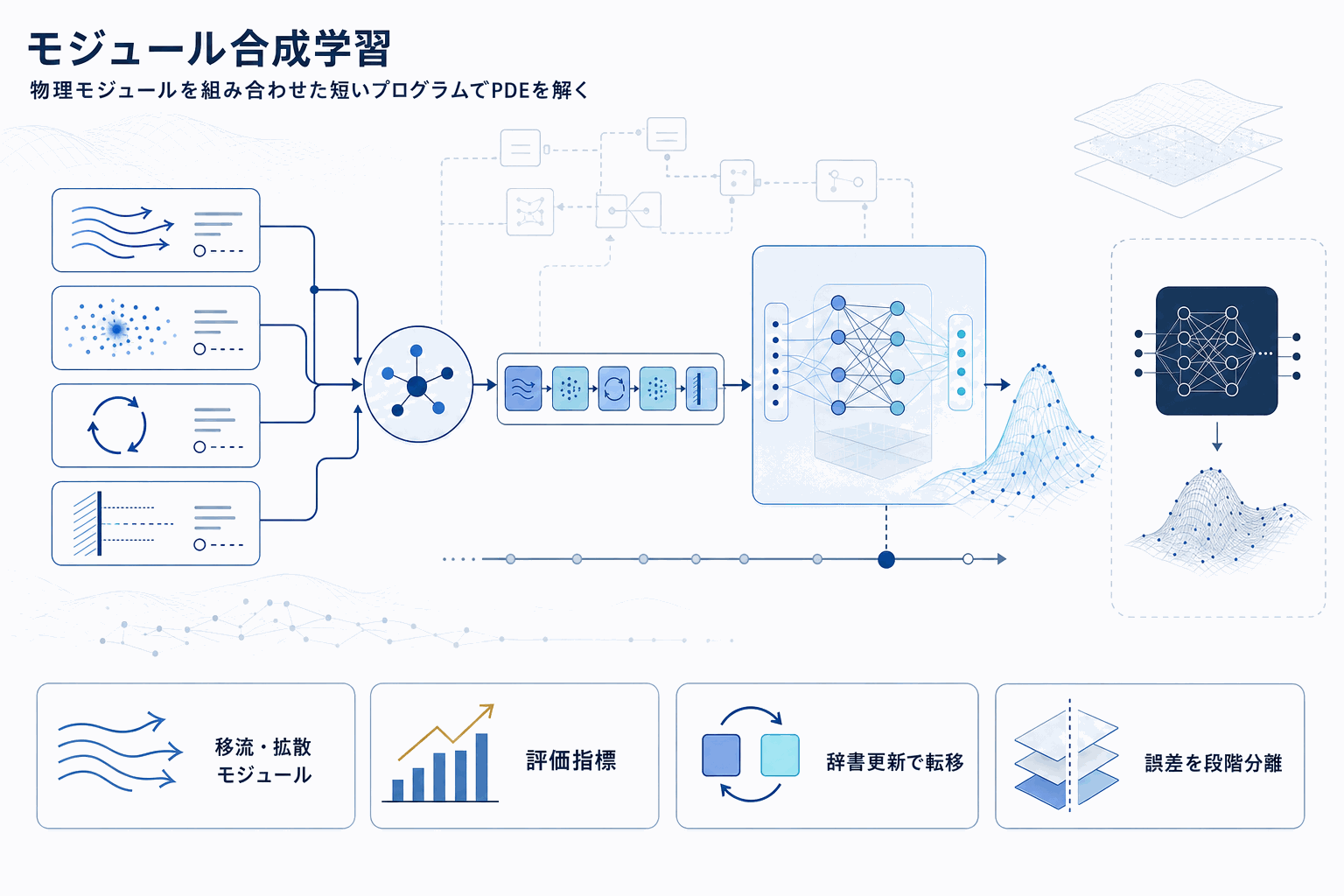
HyCOPは、偏微分方程式(PDE)の解演算子を一枚岩のニューラルネットで学習するのではなく、移流・拡散・学習済みクロージャ・境界処理といった単純なモジュールを、レジーム特徴量と状態統計に条件づけて「どのモジュールをどれだけ適用するか」という短いプログラムの方策として学習する。モジュールは数値サブソルバーでも学習済みコンポーネントでもよく、両者を同じ方策下で合成できる点がハイブリッド設計の核心になる。
実務面で大きいのは、自己回帰ロールアウトを必要とせず任意のクエリ時刻で評価できる点だ。長時間積分で誤差が累積しやすいニューラル演算子の弱点を設計段階で回避している。多様なPDEベンチマークで、モノリシックなニューラル演算子と比べてOOD精度が桁違いに改善したと報告されており、条件が訓練分布から外れる実運用の場面で効きやすい。
再利用性の観点では、境界条件の差し替えや残差補強を「辞書更新」として扱い、モジュール単位の転移学習を可能にしている。案件ごとにモデルを作り直すのではなく、辞書を入れ替えて差分学習する運用が視野に入る。
さらに、著者らは表現能力を特徴づける理論と、合成誤差とモジュール誤差を分離する誤差分解を提供している。これは単なる性能指標ではなく、どの段で精度が劣化したかを特定するプロセスレベルの診断ツールとして使える。サロゲートを意思決定に用いる場面での検証・デバッグ工程に直接組み込める点が、実装担当にとっての実利になる。