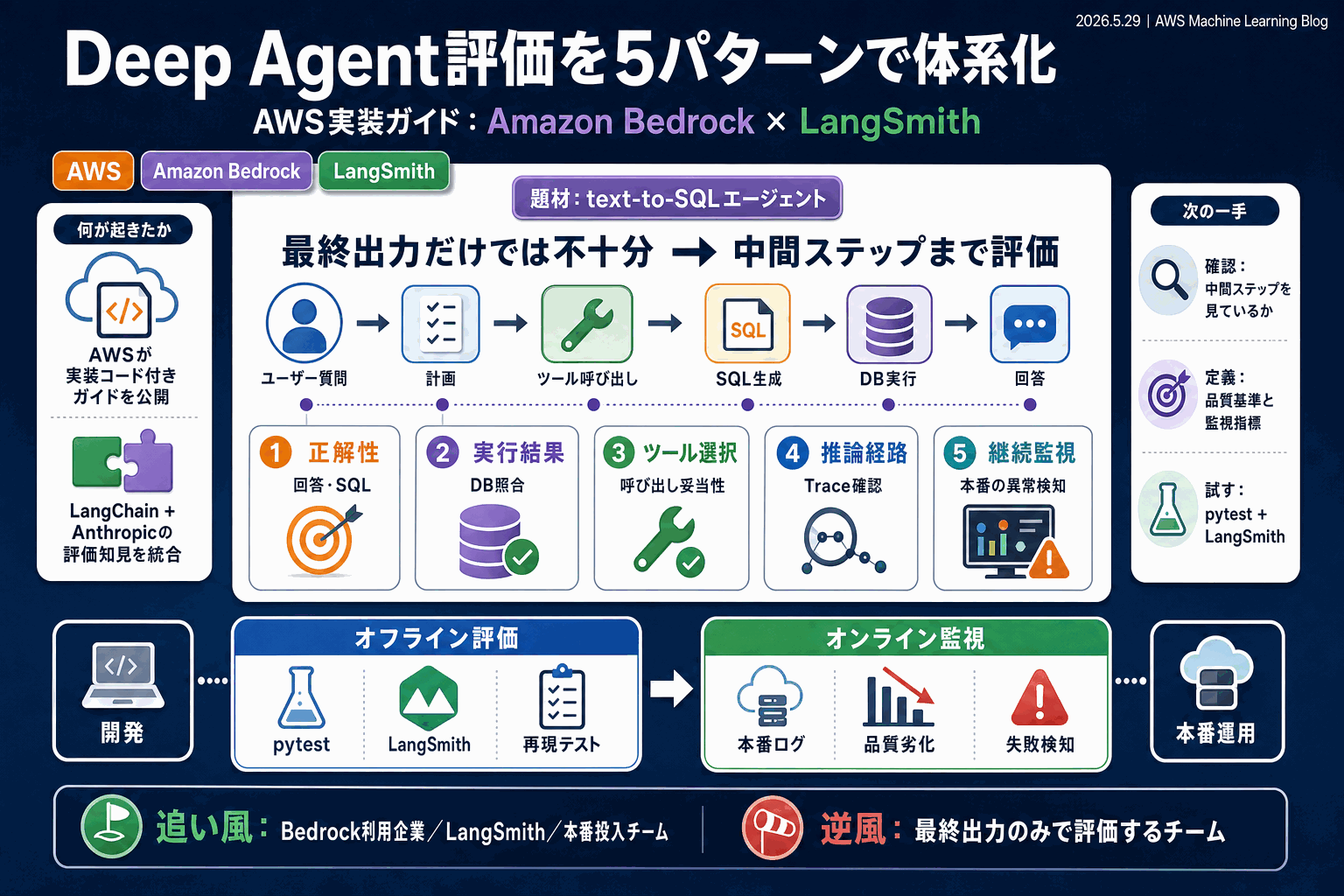
5つの評価パターンで中間ステップを捉える
AWS Machine Learning Blogが公開した本ガイドは、Deep Agent(自律的に複数ステップを実行するAIエージェント)の評価に焦点を当てている。記事は次のように目的を整理する。
apply five evaluation patterns for deep agents, build offline evaluations using pytest and LangSmith, and configure online monitoring for production.
エージェントは最終出力に至るまでに複数の判断とツール呼び出しを重ねるため、最終回答だけを採点する従来手法では、途中のSQL生成ミスや誤った経路選択を見逃す。本ガイドは5つの評価パターンを適用することで、各段階の品質を切り分ける設計を提示している。
オフライン評価と本番監視を分離する
もう1つの軸が、開発時のオフライン評価と本番運用時のオンライン監視の分離だ。オフライン側はpytestとLangSmithを組み合わせ、テストコードとしてエージェントの挙動を再現・検証する。本番側はオンライン監視を設定し、稼働中のエージェントの挙動を継続的に追う構成になっている。
題材はtext-to-SQLエージェントで、自然言語からSQLを生成するタスクは正解との照合がしやすく、評価手法を実演する素材として扱われている。基盤にはAmazon Bedrockを用い、開発から本番までのライフサイクル全体を1本の流れでカバーする。
知見の統合とスタック適合性
本ガイドはLangChainのDeep Agent評価に関する取り組みと、AnthropicのAIエージェント向けevalsガイドの知見を1つの実務手順に統合したものだ。AWSスタックでエージェントを運用する読者にとっては、Bedrock+LangSmithという具体的な構成で評価を組み立てる出発点になる。落とし穴として、text-to-SQLのように正解が明確なタスクでは評価パターンを適用しやすい一方、正解が一意に定まらない生成タスクへ転用する際は、評価基準そのものの定義から設計し直す必要がある点に留意したい。