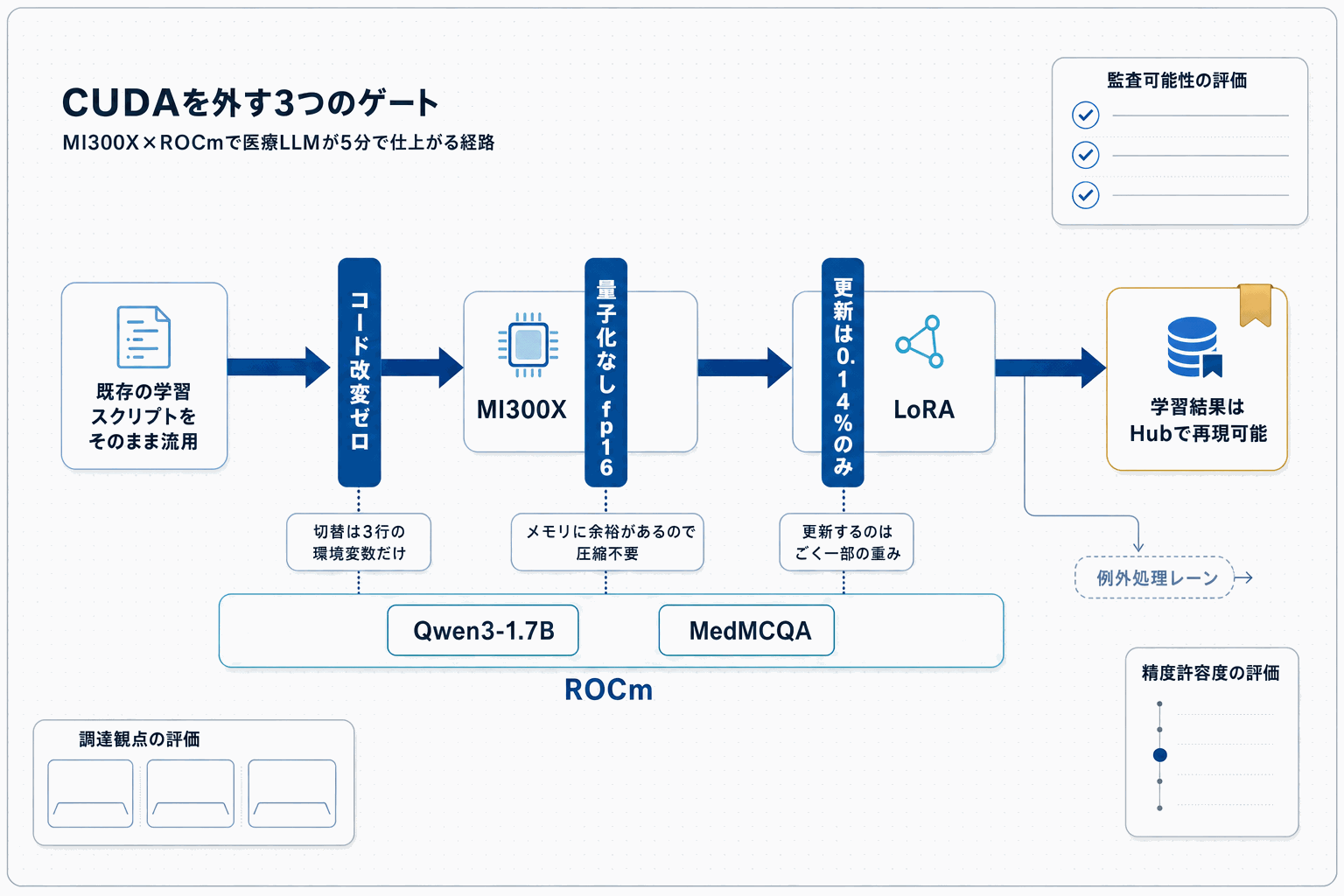
Hugging Face Blogで2026年5月8日に公開された本記事は、AMD Instinct MI300X上で医療QAモデルをLoRAファインチューニングする手順を実装コード付きで示している。ベースモデルはQwen3で、LoRA設定はrank=8、対象モジュールはq_projとv_projのみ。学習パラメータ数は全体の約0.14%(約222万パラメータ)にとどまる。
注目すべきは、MI300XのHBM3メモリ192GBという大容量により、4bit/8bit量子化を行わずfp16のままフルLoRAファインチューニングができる点である。量子化による精度劣化や実装の複雑さを回避できるため、医療のような誤差許容度が低い領域で価値が高い。学習データはMedMCQAから2,000サンプルを抽出し、2エポックの学習が約5分で完了している。
移行手順の具体性も重要だ。CUDA向けに書かれたHuggingFaceエコシステム(Transformers・PEFT・TRL・Accelerate)が、ROCR_VISIBLE_DEVICES・HIP_VISIBLE_DEVICES・HSA_OVERRIDE_GFX_VERSIONの環境変数3つを設定するだけで動作したと報告されている。コード改変が不要というのは、既存資産を持つ開発チームにとって移行コストを大きく下げる材料となる。
学習済みLoRAアダプターはHugging Face Hub(HK2184/medqa-qwen3-lora)で公開されており、実装コードもGitHubに配置されている。再現可能性が確保されている点は、医療AIという規制を意識する領域で検証や監査を行う際の前提条件を満たす。NVIDIA一択だったGPU選定に具体的な代替案が加わったという意味で、調達戦略の見直しを進める企業にとって参照価値のある事例である。