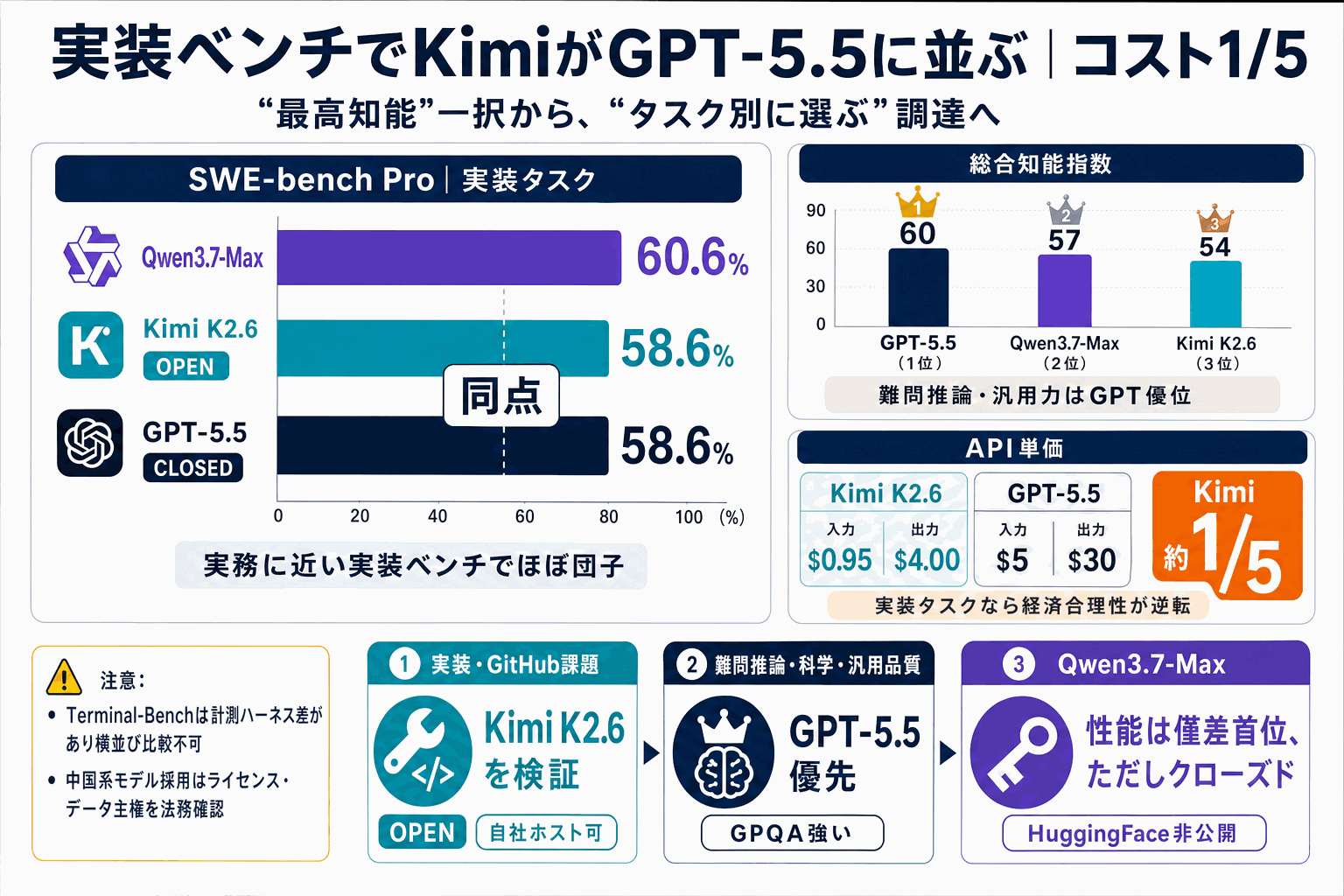
評価機関Artificial Analysisの総合指標「知能指数」と各社公称ベンチを束ねて、オープンウェイトのKimi K2.6(2026年4月20日、1T MoE/256Kコンテキスト/Modified MIT)、クローズドのQwen3.7-Max(2026年5月20日、Alibaba Cloud Summitで発表、1Mコンテキスト)、GPT-5.5(2026年4月23日、1Mコンテキスト)を比較した。
結果はタスクで割れた。実務に近いSWE-bench ProではKimiとGPT-5.5がともに58.6%で同点、Qwenが60.6%で僅差リードと団子状態。一方、総合知能指数はGPT-5.5=60 > Qwen=57 > Kimi=54で、難問推論のGPQA DiamondもGPT-5.5=93.6%が最上位とクローズド優位が残る。Terminal-Benchの見かけ差(82.7対66.7)は計測ハーネスが異なるため横並び比較できない。
構造的に効くのは価格差だ。Kimiの単価は$0.95/$4.00、GPT-5.5は$5/$30で、実装タスクなら約1/5。「最高の総合知能が要らない作業」ではオープンに寄せる合理性が生まれた。一方Qwenは最新旗艦をクローズド化し、オープン採用の候補からは外れた。