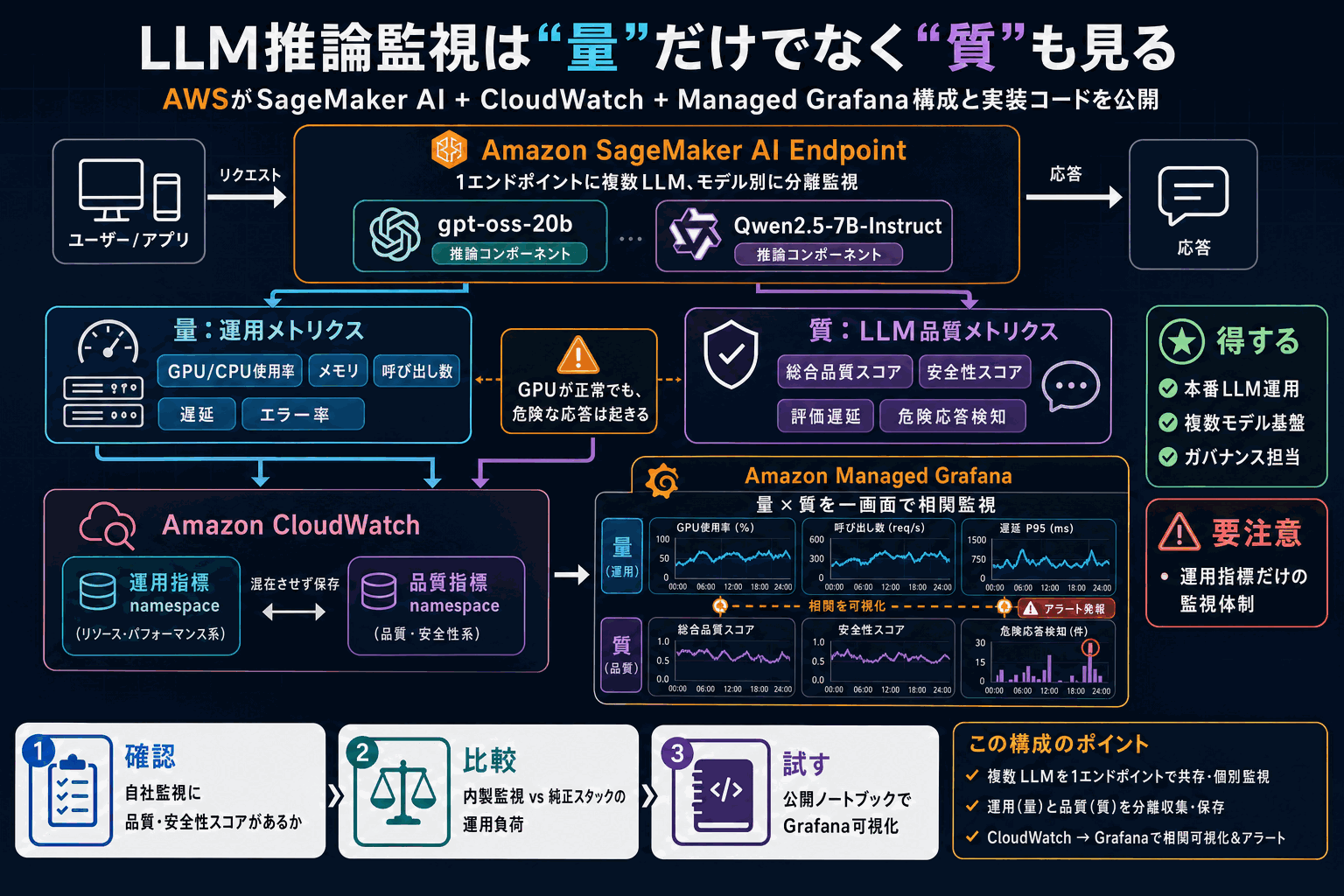
AWSは、Amazon SageMaker AIで運用するLLM推論を包括的に監視する構成と実装コードを公開した。監視は「量(インフラの稼働健全性)」と「質(モデル出力の品質)」の二側面で構成する。GPU使用率や遅延が正常でも不適切・危険な応答を返したり、逆に高品質でも過剰な資源で非効率に動く不整合は、両側面を同時に見ないと検知できない、という問題意識が出発点である。
具体的には、1つの推論エンドポイントに推論コンポーネントとして複数のLLM(例: gpt-oss-20b、Qwen2.5-7B-Instruct)を同居させ、モデルごとに分離して監視する。呼び出し数・遅延・エラー率・GPU/CPU使用率の拡張メトリクスはエンドポイント設定で有効化すると自動記録される。総合品質スコア・安全性スコア・評価遅延といった品質指標は、運用指標とは別の名前空間に保存して混在を避ける。
指標はAmazon CloudWatchに集約し、Amazon Managed Grafanaで可視化する。AWSはサンプルノートブックをGitHubで公開しており、量と質を同時に追う監視基盤を自前でゼロから組まずに再現できる。