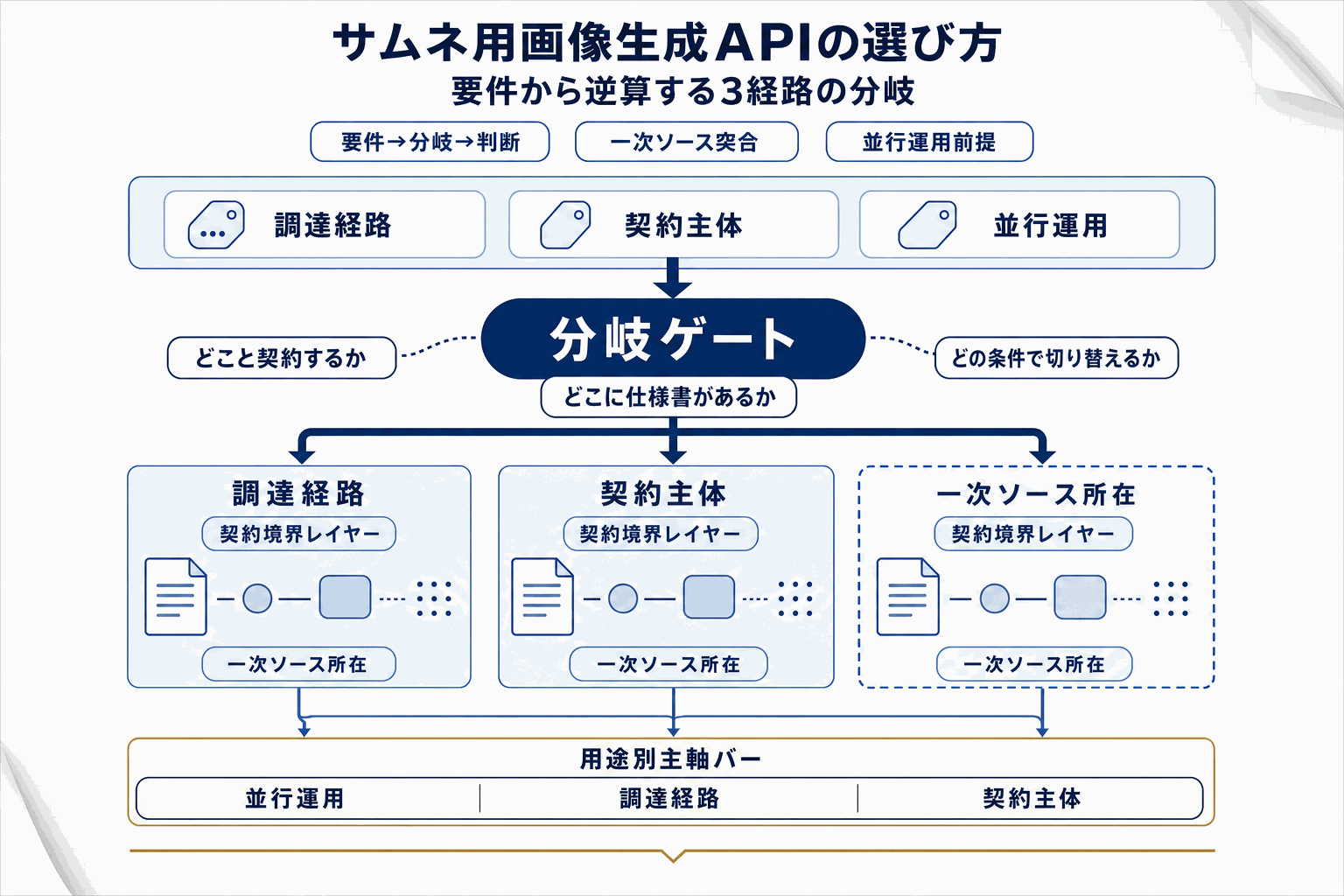
サムネイル制作向けの画像生成APIとして、OpenAI、xAI、Stability AIの3系統が公式ドキュメントを揃え、選定の前提条件が整った。
OpenAIはplatform.openai.comの『Image generation guide』で画像生成APIの使い方を整理し、developers.openai.comの『API Pricing』ページで画像生成モデルの料金を提示している。料金と仕様が同一ドメイン配下で参照できるため、見積もりから実装までの導線が短い。
xAIはdocs.x.aiの『Grok Imagine Image Quality』モデルページと『Image generation guide』を公開しており、画像品質モデルとしての位置づけと利用方法を独立したページで示している。X(旧Twitter)プラットフォームと同じ事業者が提供する点が特徴で、xAI APIに既に接続している開発者にとっては追加の契約障壁が小さい。
Stable Image UltraはAmazon Bedrock経由で提供される形態をとり、docs.aws.amazon.comに『Stable Image Ultra request and response』としてリクエスト/レスポンス仕様が掲載されている。契約主体がAWSとなるため、既存のAWSガバナンス・課金統合の中に画像生成を組み込める。
3社の違いは性能差というより、調達経路と契約主体、ドキュメントの構成にある。サムネ制作の意思決定では、まず月間生成数と解像度要件を定義し、次に料金ページ・モデルページ・Bedrockリクエスト仕様を一次ソースで突き合わせる順序が現実的だ。複数APIを並行運用すればベンダーロックインを避けつつ、用途別に最適なものを選べる。