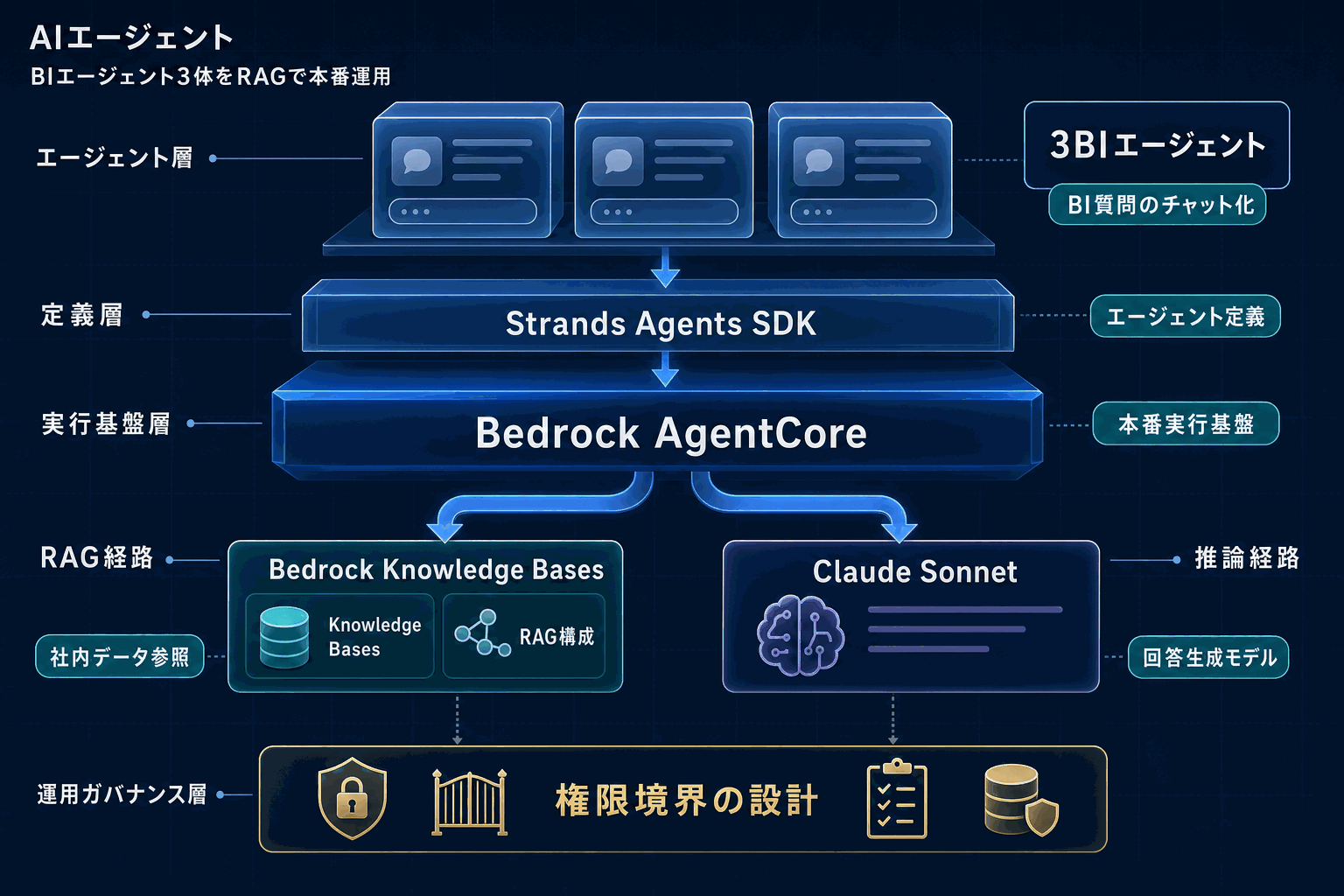
AWS Machine Learning Blogが2026年5月22日に公開した記事では、物流企業OPLOGがAmazon Bedrock AgentCore上に3つのビジネスインテリジェンス(BI)エージェントを構築した過程が示されている。基盤モデルにはAnthropicのClaude Sonnet、データ参照層にAmazon Bedrock Knowledge Basesを用いたRAG構成を採用し、エージェント定義はStrands Agents SDKで記述している。
OPLOG developed three AI agents using the Strands Agents SDK, deployed them to Amazon Bedrock AgentCore, and integrated Amazon Bedrock with Anthropic's Claude Sonnet and Amazon Bedrock Knowledge Bases for Retrieval Augmented Generation (RAG).
なぜ「事例」として読むべきか
AgentCoreはエージェント実行基盤として提供されているが、社内BI用途で実運用に乗せた事例の公開は限定的だった。今回のブログは、SDK選定(Strands)、モデル選定(Claude Sonnet)、データ層(Knowledge Bases)の組み合わせを具体名で示しており、同種のBIチャット要件を持つチームが「何をどの順で組むか」をそのまま参照できる。
実装着手時の落とし穴
ソースに明記されていないが、Knowledge Basesに投入する社内データの権限境界、エージェントが呼び出すツールの監査ログ、Claude Sonnetへ渡すコンテキストのPII除去ポリシーは、各社が自前で設計する必要がある。同日には『Break the context window barrier with Amazon Bedrock AgentCore』も公開されており、長文コンテキストを扱う際のメモリ設計と合わせて読むと、運用上のボトルネックを早期に切り分けられる。