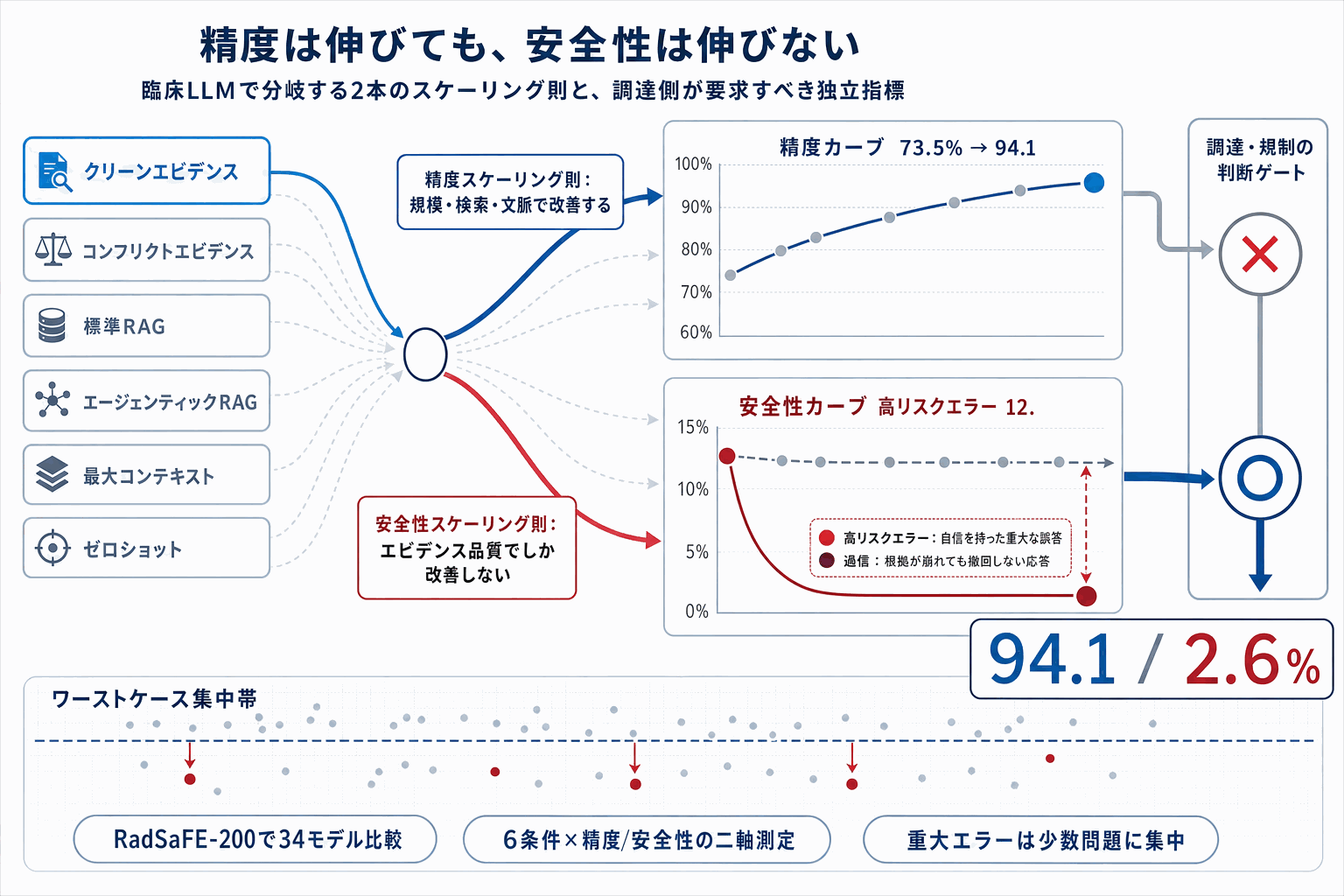
この研究は、臨床LLMを安全に使うための前提を根本から問い直す内容になっている。従来、モデル規模や文脈長、検索の複雑度、推論時計算を増やせば精度が上がり、精度が上がれば安全性も上がるという暗黙の期待があった。しかし医療では、平均精度よりも少数の「確信をもった重大エラー」が患者アウトカムを左右する。
研究チームは、この問題を測定するためのフレーム「SaFE-Scale」と、放射線領域200問の安全性評価ベンチマーク「RadSaFE-200」を提示した。臨床医が定義したクリーンエビデンス・コンフリクトエビデンス、そして高リスクエラー・安全でない回答・エビデンス矛盾といったオプションレベルのラベルが付与されている。
34のローカルLLMを、ゼロショット、クリーンエビデンス、コンフリクトエビデンス、標準RAG、エージェンティックRAG、最大コンテキストの6条件で比較した結果、クリーンエビデンス条件だけが平均精度を73.5%から94.1%へ押し上げ、高リスクエラーを12.0%から2.6%、矛盾を12.7%から2.3%、危険な過信を8.0%から1.6%まで下げた。
一方で標準RAGおよびエージェンティックRAGは、この安全性プロファイルを再現できなかった。エージェンティックRAGは標準RAGより精度と矛盾では改善したが、高リスクエラーと危険な過信は依然として高水準に残った。最大コンテキストプロンプトはレイテンシを増やしたが安全性ギャップを埋めず、推論時計算の追加も限定的な効果にとどまった。
ワーストケース分析では、臨床的に重大なエラーが少数の質問に集中していた。安全性は規模拡大の副産物ではなく、エビデンス品質、検索設計、コンテキスト構築、集合的な失敗挙動によって形作られる配備特性だと結論づけられている。