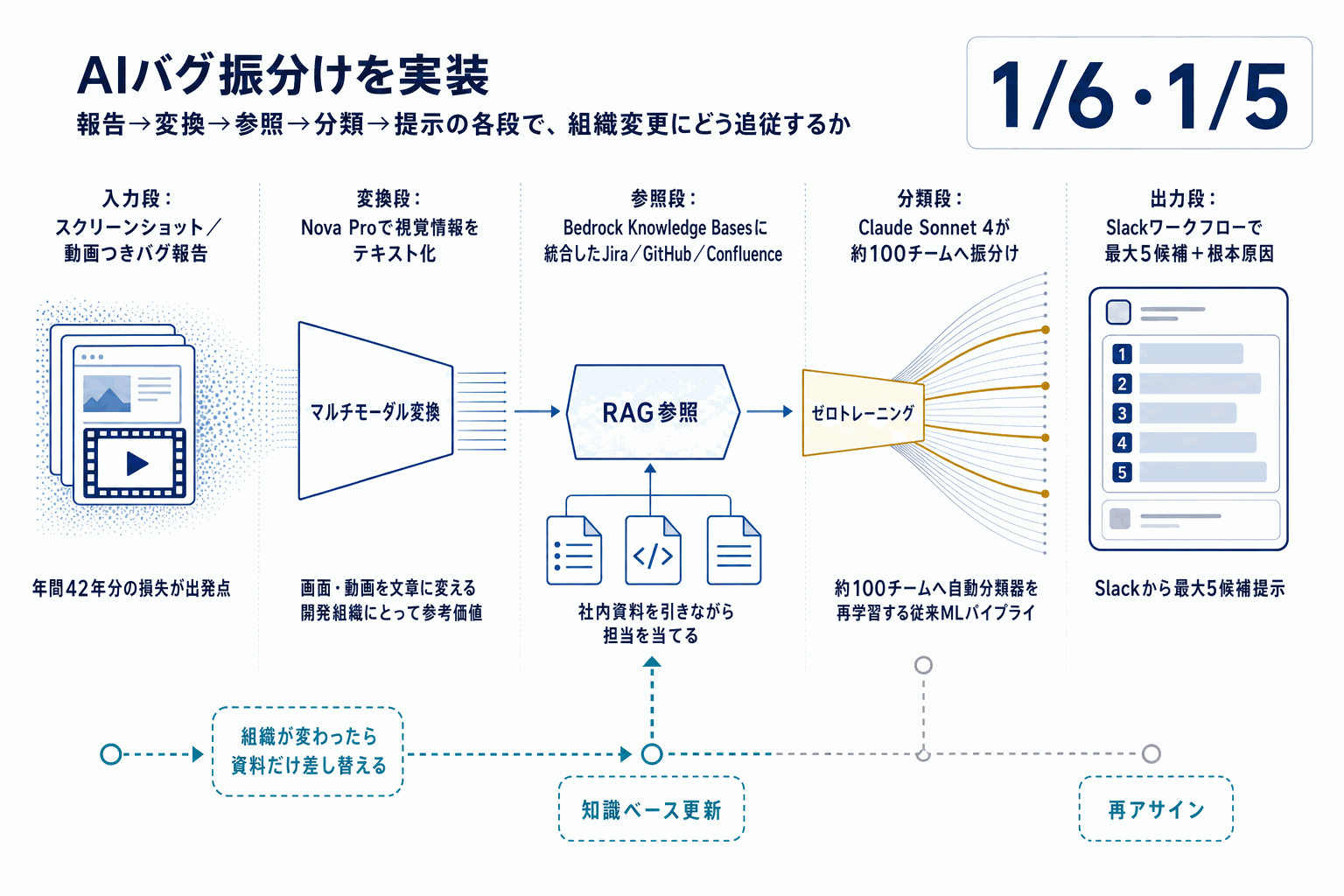
AWSのMachine Learningブログで、コラボレーションSaaSを提供するMiroが、社内のバグチケット振り分けにAmazon Bedrockを導入した事例が公開された。従来は報告されたバグを担当チームへ割り当てる工程に時間がかかり、解決までに数日を要することがあったが、Bedrockに統合されたAnthropic Claudeを用いた構成により、解決リードタイムを「数日」から「数時間」へ短縮したとされる。
構成の要点は、過去のバグチケットをナレッジソースとしたRAGと、Claudeの拡張思考を組み合わせ、再現手順が曖昧なバグ報告からもコンポーネントと所有チームを推定できるようにした点にある。Anthropicの公開資料でも、拡張思考は分類・原因推定タスクで思考過程を可視化しながら判断できる仕組みとして説明されており、Miroの用途と整合する。
読者にとっての含意は三つある。第一に、ITSM領域でマネージドLLMを使う具体的な参考実装が増えたこと。第二に、自前モデルの学習や専用MLパイプラインを構築しなくても、既存チケットデータをRAGで参照させる構成で実用水準に達し得る点が示されたこと。第三に、社内バグ情報という機密データを扱うため、Bedrockのデータ取り扱い条件を社内規程と突き合わせる作業が、PoC前の前提作業として必要になることだ。
日本企業が同様の構成を試す場合、まずは現行の振り分けルールでの精度・初回応答時間・解決時間をベースラインとして測り、その上で同一データに対するBedrock+Claudeの結果を比較する流れが、最短で投資判断に到達する手順となる。