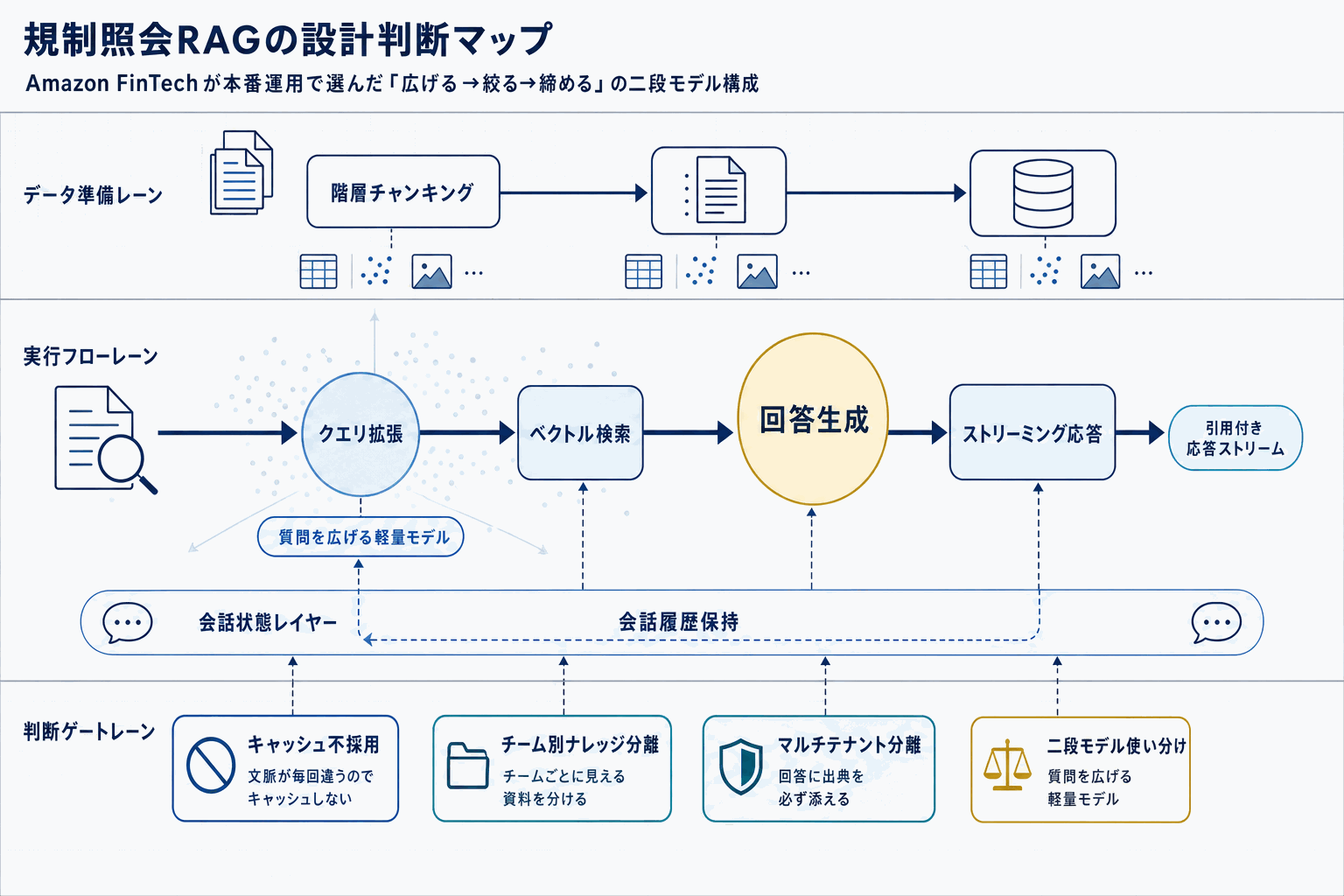
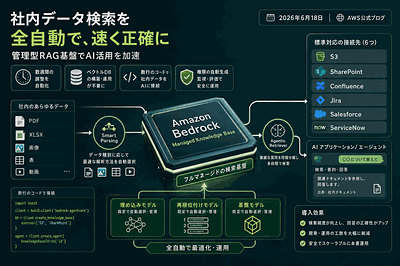
AWS Machine Learning Blogが2026年5月13日に公開した本記事は、Amazon自身の財務部門(Amazon Finance)が規制当局からの照会対応に生成AIをどう組み込んだかを解説した一次情報である。中核となるのはAmazon Bedrockによる回答ドラフト生成と、Amazon Comprehendによるエンティティ抽出を組み合わせたRAGパイプラインで、関連ドキュメントの検索精度を高めるためにクエリ拡張戦略(arxiv.org/html/2407.12325v1で議論される手法系統)を採用している点が特徴になる。
読者にとっての価値は2点ある。第一に、規制対応というハルシネーションが法的リスクに直結する領域で、Amazonが「生成AIはドラフトと検索支援」「最終回答は人間」という役割分担を採用した事実が確認できることだ。日本の金融庁照会、個人情報保護委員会からの問い合わせ、税務調査対応など、同型の業務を抱える部門は、この境界線をそのまま自社ガバナンスの初期案として流用できる。
第二に、構成部品が汎用的なBedrockとComprehendである点だ。専用の規制対応SaaSを購入せずとも、既にAWSを使う企業ならアカウント内で同型のPoCを起動できる。一方で落とし穴として、ブログには具体的な処理時間削減率や運用コストの公開数値は明示されていない範囲があり、自社で再現する際は照会1件あたりの作成時間・差し戻し率・引用元の正確性を独自KPIとして測定する必要がある。同種の社内事例としてAWS Industries Blogでも金融機関のドキュメント検索事例が公開されているが、本記事は「Amazon自身が使っている」という説得力で差別化される。