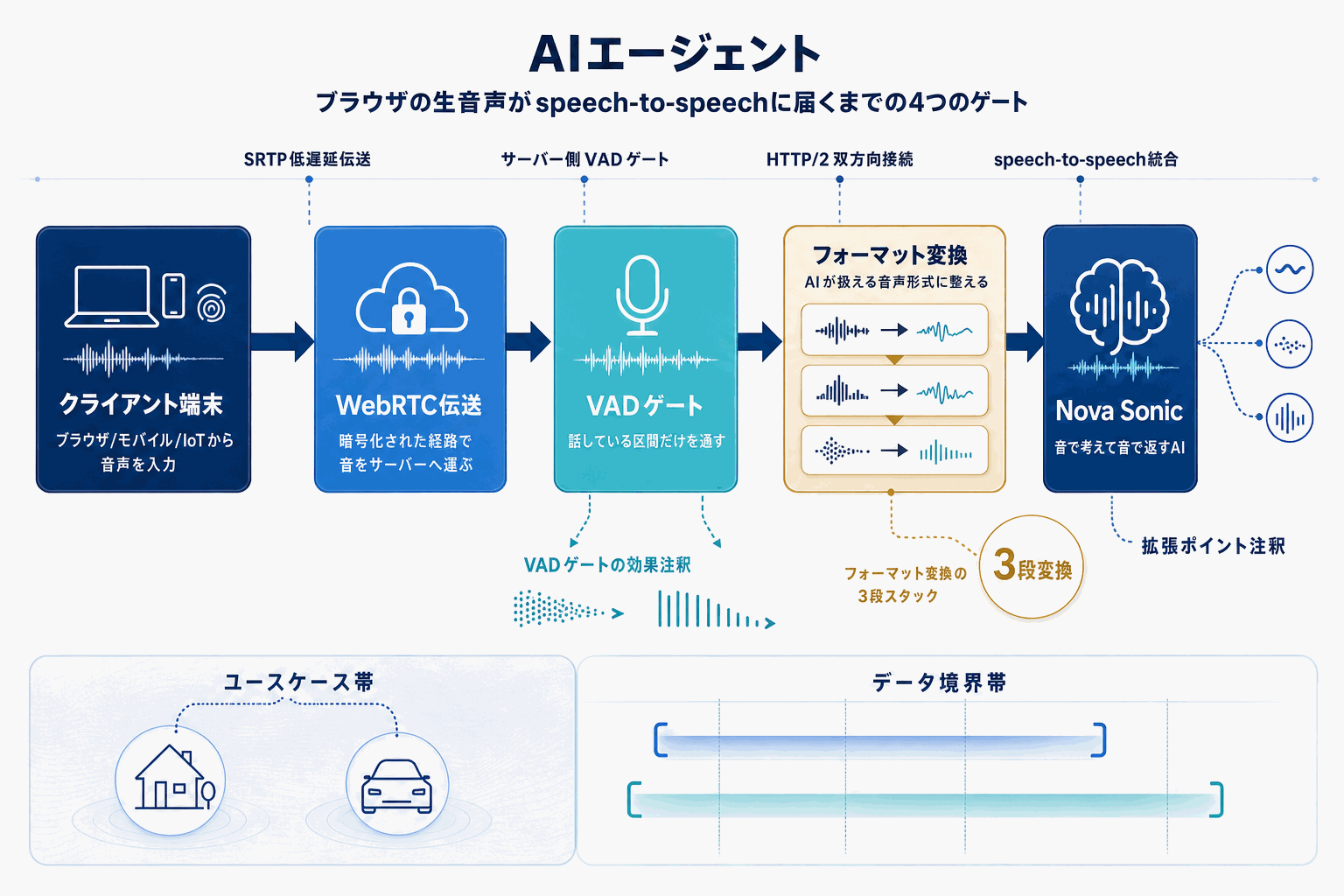
AWSが、自社の音声特化モデルAmazon Nova SonicとWebRTCを組み合わせたリアルタイム音声ストリーミングアプリの構築方法を公開した。WebRTCはブラウザやモバイルアプリで広く採用されている双方向リアルタイム通信の標準プロトコルで、これを音声AIの入出力レイヤーに据えることで、ユーザーの発話とモデルの応答を持続接続上でやり取りする構成が成立する。
背景には、音声AIの競争軸が「音声→テキスト→LLM→音声合成」というパイプライン型から、音声を直接入出力するリアルタイム型へ移っている流れがある。OpenAIのRealtime APIやGoogleのGemini Liveなど、各社が低遅延な音声I/Oを前面に出すなかで、AWSもNova Sonicを軸に同じ土俵へ参照実装を提示した形となる。
実装観点では、WebRTCのシグナリング、メディアサーバー、Nova Sonicへのストリーム連携という3層をどう設計するかが鍵になる。AWS基盤上で完結させられる利点は、既存のIAM・VPC・ログ基盤・コンタクトセンター製品(Amazon Connect等)との接続のしやすさに直結し、規制業種でも採用検討に入りやすい。
読者が実装に踏み出す際の落とし穴としては、WebRTCのNAT越え・TURNサーバー運用コスト、音声の割り込み(barge-in)処理、ストリーム単位の課金が想定外に膨らむ点が挙げられる。公開された手順をそのまま動かす前に、遅延・コスト・同時接続数の3軸でベンチマークを取り、既存の音声基盤と数値比較してから本番投入の判断に進むのが現実的なルートとなる。