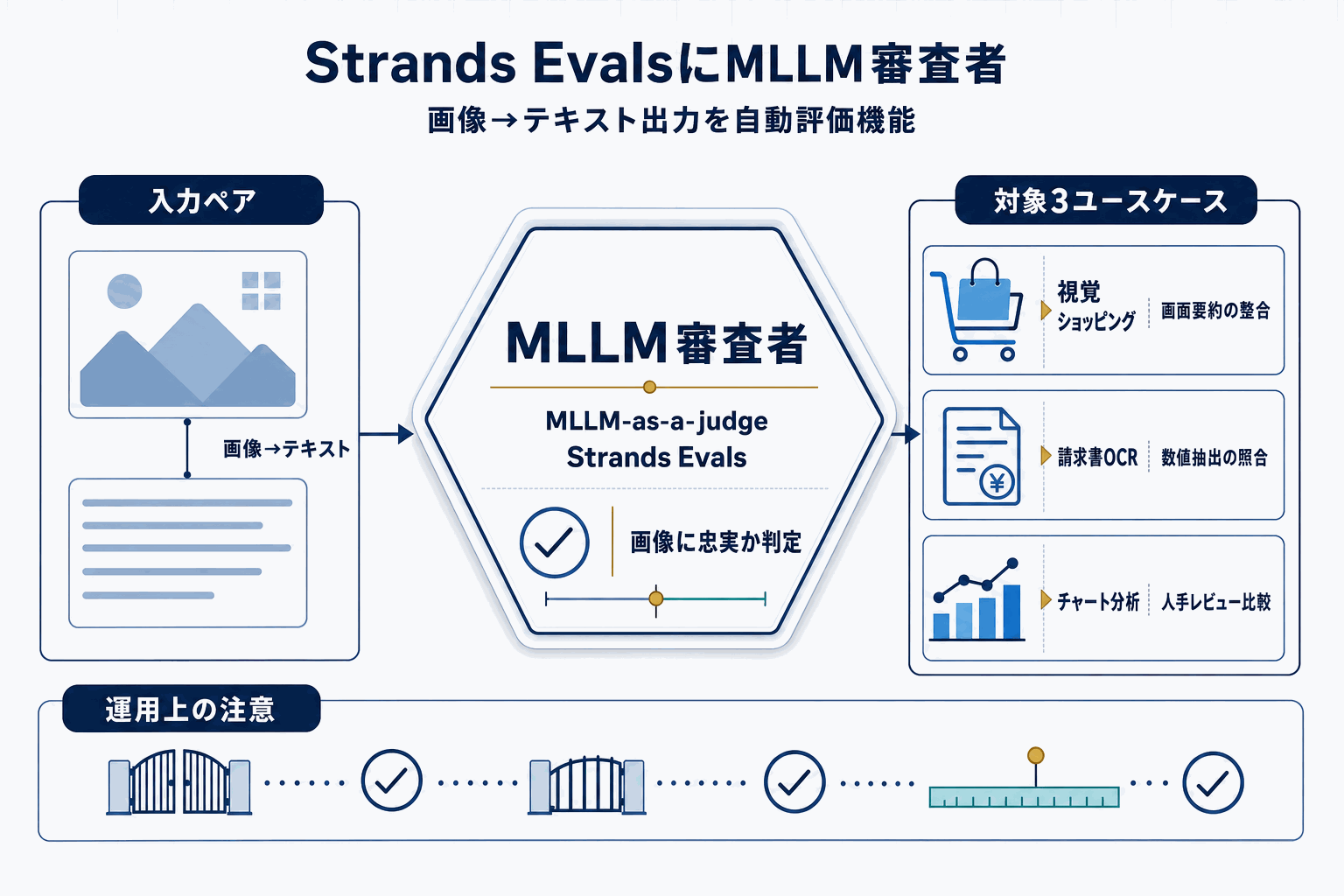
AWS Machine Learning Blogが2026年5月21日に公開した記事で、Strands Evalsに画像→テキストタスク向けのマルチモーダル評価機能が追加された。中核となるのは「MLLM-as-a-judge」、つまりマルチモーダル大規模言語モデル自身を審査者として用い、生成テキストが入力画像に忠実かを判定する仕組みである。
対象ユースケースとして公式が挙げるのは、視覚ショッピング、画像・文書理解、チャート分析の3領域。たとえば商品画像のキャプションが画像内容と整合しているか、請求書から抽出した合計金額が原本と一致しているか、画面要約が画像の中身を正しく反映しているかといった、テキストのみの評価器では原理的に検証不可能な観点を自動化する。
実務上の意味は2つある。第一に、画像系AI機能の品質保証パイプラインが標準化される点。これまで開発チームは独自の評価スクリプトや人手チェックに頼っていたが、評価フレームワーク内で完結するため、CI/CDへの組み込みが容易になる。第二に、ハルシネーション検出経路の追加。金額や数値を扱う文書処理では出力誤りが事業リスクに直結するため、機械的な事前検出手段が増えることは運用設計に影響する。
読者が着手時に注意すべき点として、MLLM審査者自身もハルシネーションを起こす可能性がある以上、人手レビューとの一致率をまず測定し、信頼できるタスク領域を切り分けてから本番投入する手順を踏む必要がある。公開数値ベースのコスト比較は現時点で出ていないため、自社サンプルでの試算が前提となる。