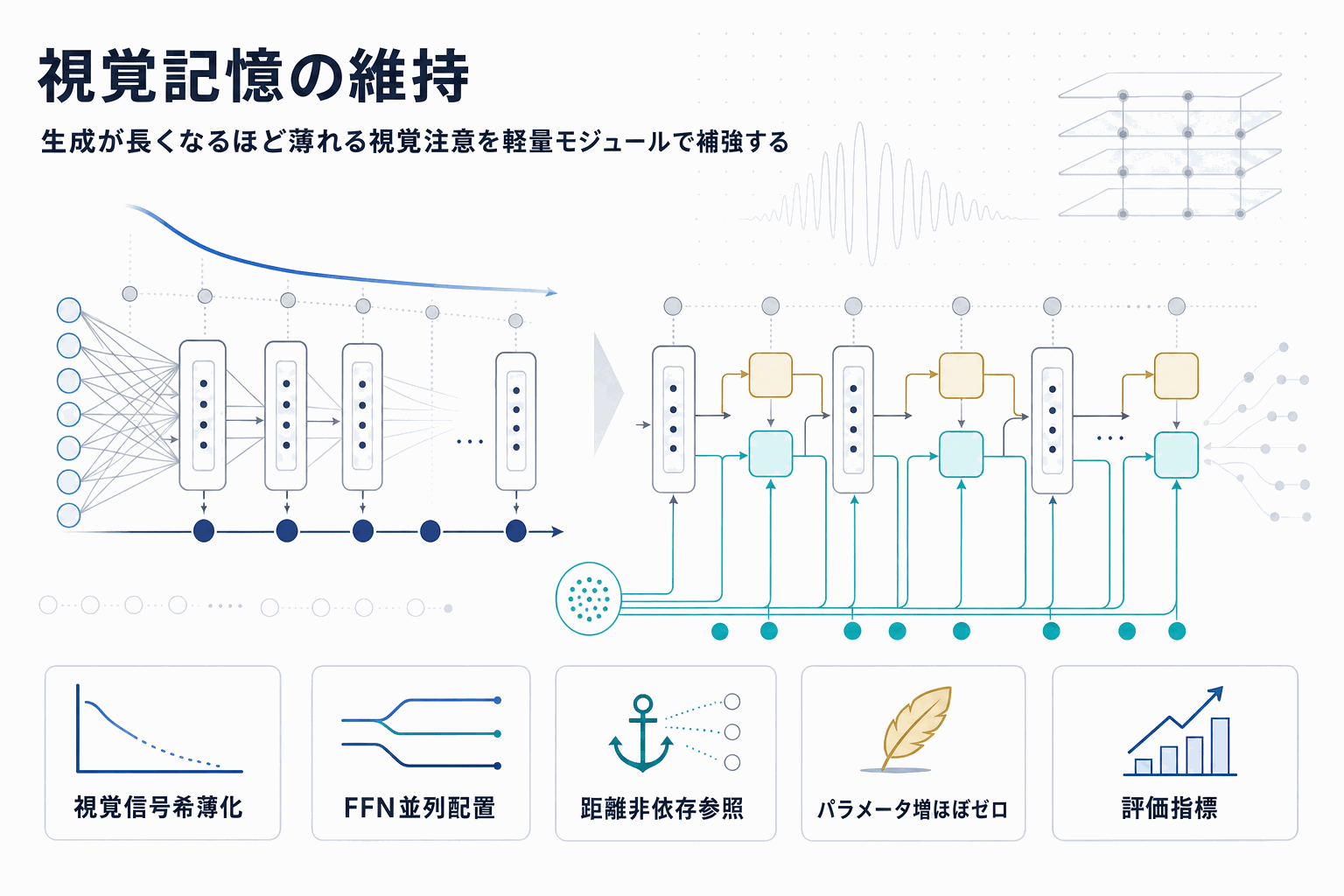
自己回帰型のLVLMには、テキスト履歴が蓄積するほどアテンションの分配関数が膨張し、視覚トークンへの注意が生成長に反比例して減衰するという構造的な弱点が存在する。本論文はこれを「Visual Signal Dilution」と名付け、長文生成や多段の視覚推論で精度が崩れる原因として定式化した。
提案手法のPersistent Visual Memory(PVM)は、各層のFeed-Forward Networkと並列に挿入される軽量な学習可能モジュールである。通常のアテンション経路が履歴の長さに影響を受けるのに対し、PVMは距離に依存しない検索経路として視覚埋め込みを直接供給する。これにより、生成がどれだけ進んでも画像側の情報が構造的に参照され続ける。
検証はオープンソースのQwen3-VL 4Bおよび8Bで行われ、パラメータ増加をほぼゼロに抑えつつ、複雑推論を要するタスクで平均精度が一貫して向上した。さらに内部分析では、PVM導入モデルが長さによる信号減衰に耐性を示すこと、内部の予測収束が加速することが報告されている。
実務的な含意は、巨大モデルに置き換えるのではなく、小型LVLMへの軽量モジュール追加で長文視覚推論の品質を底上げできるという選択肢が具体化した点にある。推論コスト境界を維持したい事業者にとって、既存資産へのアドオン改修は現実的な改善パスとなる。一方で、ベンチマーク詳細や未公開タスクでの再現性は各自で検証する必要があり、自社データに対する視覚根拠一貫性の測定が導入判断の前提となる。