学習データの乏しい言語をどう乗り越えたか
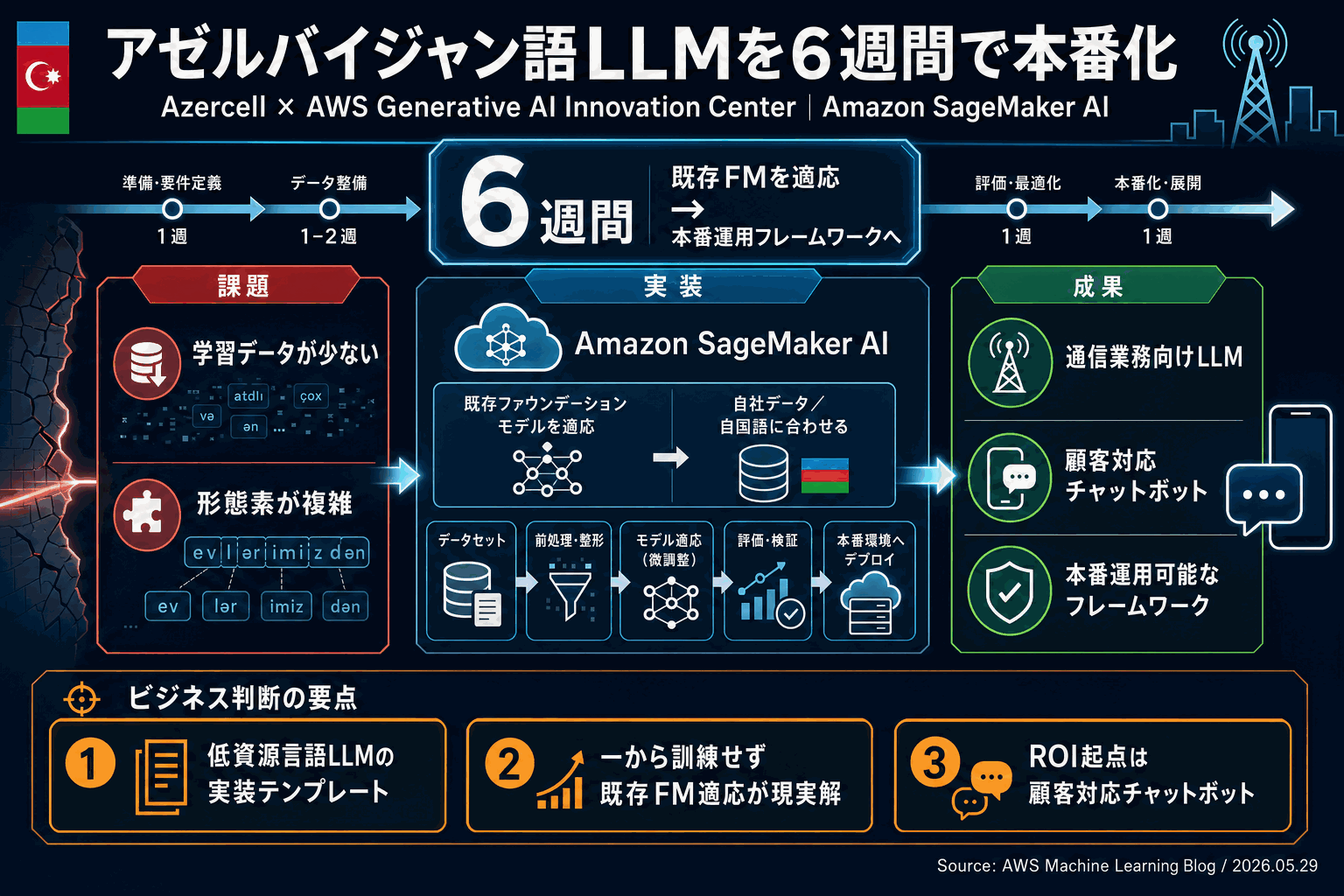
アゼルバイジャン最大の通信事業者Azercell Telecom LLCは、通信業務と顧客対応チャットボット向けにアゼルバイジャン語の大規模言語モデルを構築したいと考えていた。課題は明確で、形態素が豊かな言語であること、学習データが限られること、そしてアゼルバイジャン語での効率的なLLM訓練に既存の設計図が存在しないことだった。
Azercell worked with the AWS Generative AI Innovation Center to establish a production-ready framework on Amazon SageMaker AI.
AzercellはAWS Generative AI Innovation Centerと協業し、6週間でAmazon SageMaker AI上に本番運用可能なフレームワークを確立した。一から基盤モデルを訓練するのではなく、既存のファウンデーションモデルを当該言語に適応させるアプローチが採られている。
なぜこの事例が実装者に効くのか
英語以外の言語、とりわけ学習データが少なく文法構造が複雑な言語でのLLM構築は、多くの非英語圏企業が直面する共通の壁である。本事例は「既存の設計図がない」状態から出発し、本番に乗せられるフレームワークまで6週間で到達したという工数感を提示している点に価値がある。
通信事業者の顧客対応チャットボットという、効果測定がしやすいユースケースを起点に設計されているため、同業他社が自社の導入規模やROIを見積もる際の参照点になる。自社の言語・自社のデータでモデルを適応させ自前で運用する経路は、外部の汎用APIに依存しない設計を望む事業者にとって、現実的な選択肢として提示された。実際に適用を検討する際は、自社が扱う言語のデータ量と、本事例が前提にしている学習データ規模との差を最初に切り分ける必要がある。