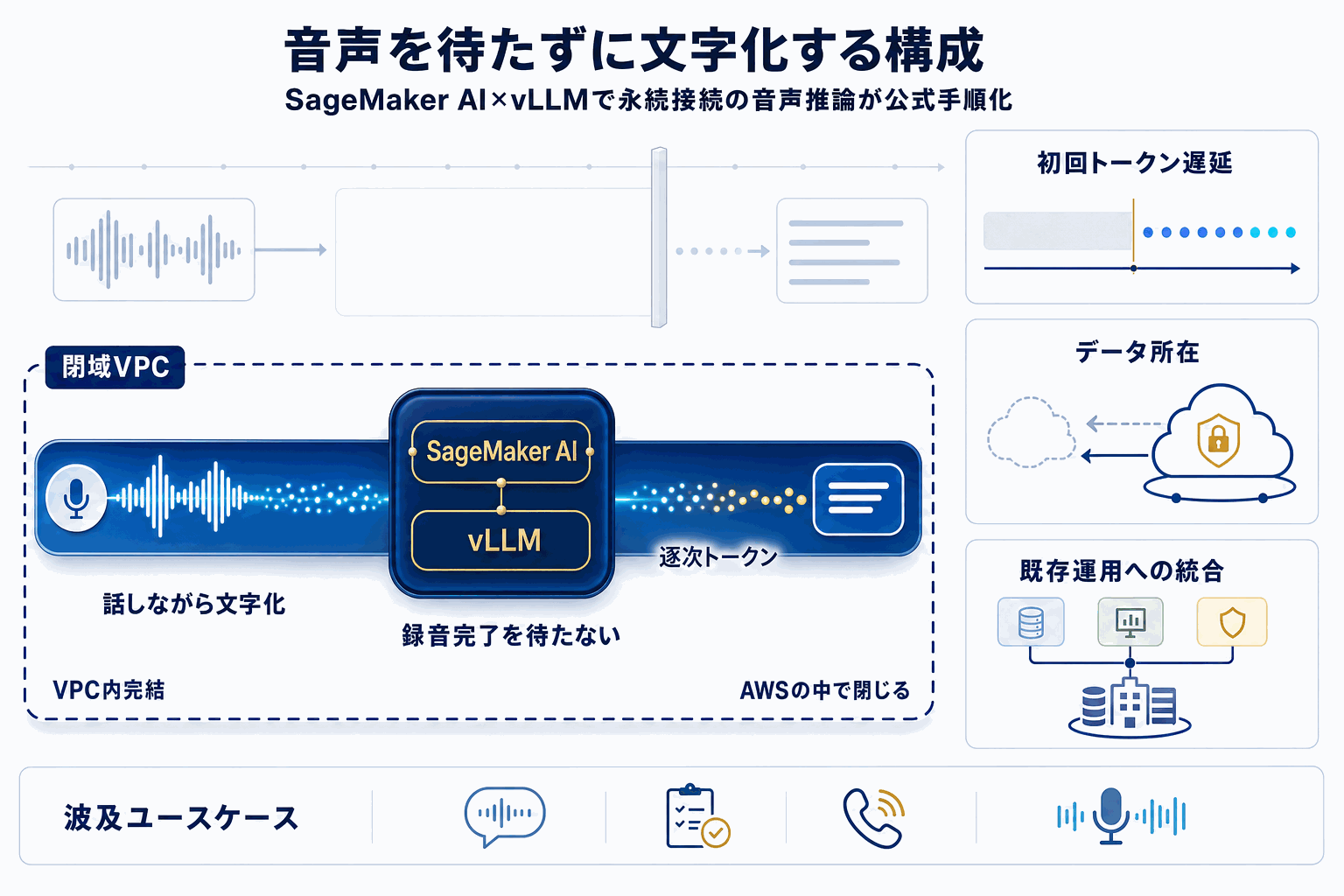
AWSは2026年5月21日、Amazon SageMaker AIとvLLMを使ってリアルタイム音声アプリケーションを構築する手法を機械学習公式ブログで公開した。音声エージェント、ライブ字幕、コンタクトセンター解析、アクセシビリティ支援といった用途は、音声をストリームで入力しつつ同時に文字起こしを単一の永続接続で受け取る必要がある。
従来のリクエスト・レスポンス型推論では、音声録音全体を受信し終えるまで文字起こしを開始できず、リアルタイム性を求める用途では遅延が許容範囲を超えていた。今回示された構成は、vLLMをSageMaker AI上で動かしながら永続的なコネクションで逐次推論を返す形を取ることで、この制約を解消するアプローチを採る。
読者の意思決定上のポイントは三つある。第一に、これまで外部のリアルタイムSTT API(Deepgram、AssemblyAI、Google等)に依存していたアーキテクチャを、AWSアカウント内VPCで完結させる選択肢が公式手順として整備された点。第二に、SageMakerの既存IAM・課金・監視基盤の中に音声ワークロードを取り込めるため、運用組織を増やさずに済む点。第三に、vLLMの汎用LLM推論基盤に音声系の活用パターンが乗ることで、テキスト・音声を同居させる構成の自由度が増す点である。
一方、公式ブログ単体では具体的な遅延数値、同時接続上限、コスト試算は本記事執筆時点で読者が自分の要件に当てはめて測る必要がある。コンタクトセンター録音や会議字幕は個人情報を含むため、データ所在の説明責任を負う事業者にとっては外部SaaS送信を回避できるメリットも比較材料となる。