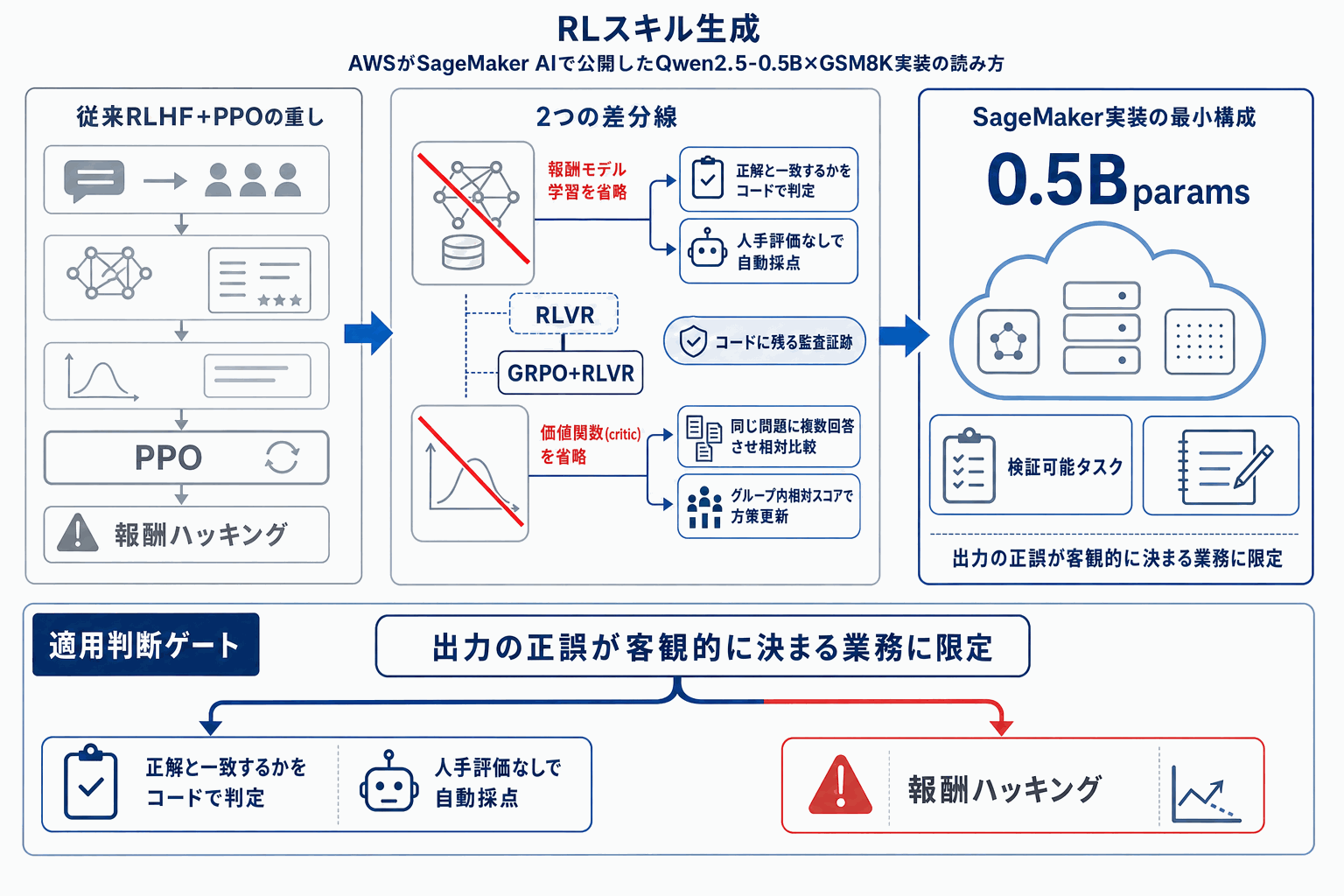
AWSは2026年5月8日、Machine Learning Blogで「Overcoming reward signal challenges」と題した記事を公開し、SageMaker AI上でGRPO(Group Relative Policy Optimization)と検証可能報酬による強化学習(RLVR)を組み合わせてLLMをファインチューニングする手順を示した。題材はQwen2.5-0.5BをGSM8K(小学校レベルの数学問題7,473件)で学習させる構成で、8-shotのfew-shot例を組み合わせ、ml.p4d.24xlargeでの分散マルチGPU学習をSageMaker Training Jobsから起動する。
RLVRの要点は、報酬モデルを別途学習せず、出力が正解と一致するかをプログラム的なルールで判定して報酬を返す点にある。数学の最終解、コード実行結果、記号操作の正規化後の一致など、客観的に正誤が決まる領域で強力に機能する。人手評価を介さないため報酬ハッキングのリスクが構造的に小さく、評価ロジックがコードとして残るため監査性も高い。
GRPOはPPOで必要だった価値関数(critic)を省き、同じプロンプトに対する複数出力のグループ内相対スコアで方策を更新する。これによりメモリ負荷が下がり、0.5Bクラスでも単一の大型インスタンスで現実的に回せる。
この手法はDeepSeek-R1の公開以降、推論特化モデルの標準レシピとして急速に普及してきたが、クラウドの公式ブログでエンドツーエンドの再現ノートブックまで揃った意味は大きい。自社に検証可能タスク(SQL生成、スキーマ変換、数値計算、構造化出力)を持つ企業にとって、Bedrockの汎用API呼び出しと、自前で小型モデルを強化するルートを比較する材料が一段揃った。