Amazon SageMaker AI MLflow Apps が MLflow v3.10 をサポートした。今回の目玉は、生成AIアプリの品質管理を実験管理と同じ器で扱えるようにした点である。
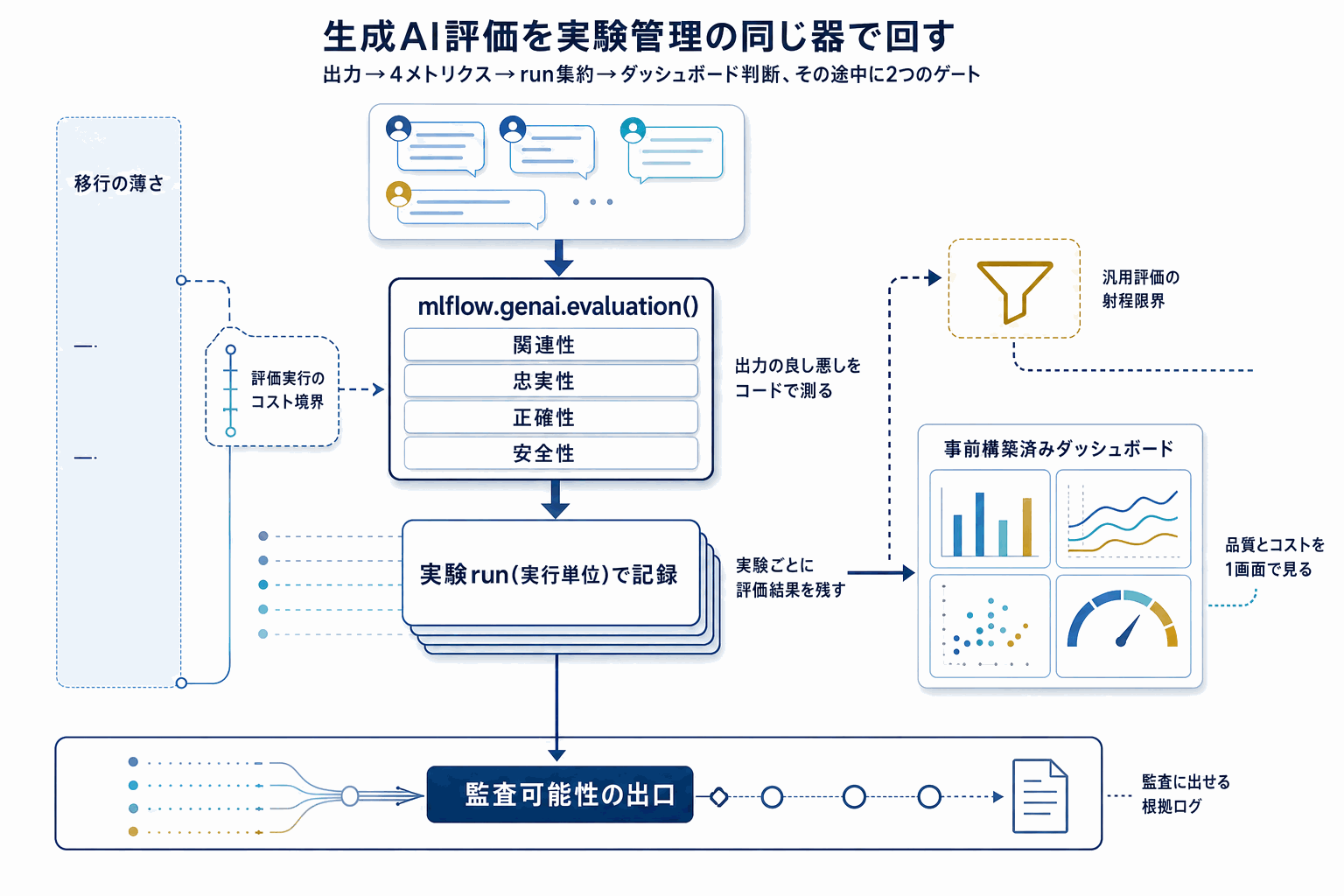
中核となるのは mlflow.genai.evaluation() API で、関連性(relevance)・忠実性(faithfulness)・正確性(correctness)・安全性(safety)の4つの組み込みメトリクスでアプリ出力を定量評価できる。従来、RAG やエージェントの品質評価は各チームが自前の評価スクリプトを書き、結果を別ツールで管理することが多かった。今回の統合で、実験の run 単位に評価結果が紐づき、バージョン間比較やリグレッション検知が標準ワークフローに入る。
観測性の面では、レイテンシ分布・リクエスト数・品質スコア・トークン使用量を表示する事前構築済みダッシュボードが追加された。コスト監視と品質監視を1画面で追えるため、プロダクション運用時のチューニング判断が速くなる。
移行コストは低い。pip install mlflow==3.10.1 と sagemaker-mlflow==0.3.0 の2パッケージで完結し、SageMaker AI サーバーレスモデルカスタマイズおよび SageMaker Unified Studio でも同じ仕組みが利用できる。
実装着手時の落とし穴として、組み込みメトリクスはあくまで汎用評価であり、業務固有の正解基準(例: 社内規程に沿った回答か、特定フォーマット遵守か)をそのまま測れるわけではない。カスタムメトリクスの併用と、評価用データセットのバージョン管理を同時に設計する必要がある。また、評価実行自体が LLM 呼び出しを伴うため、トークンコストを実験コストとして別枠で測ることが運用上の鍵になる。公開された価格情報はないため、初期は小さいデータセットで試して単価を実測する流れが現実的である。