Sun FinanceがAWS Machine Learning Blogで公開した本人確認パイプラインの事例は、生成AIを規制産業の基幹業務に適用する際の設計指針として注目度が高い。
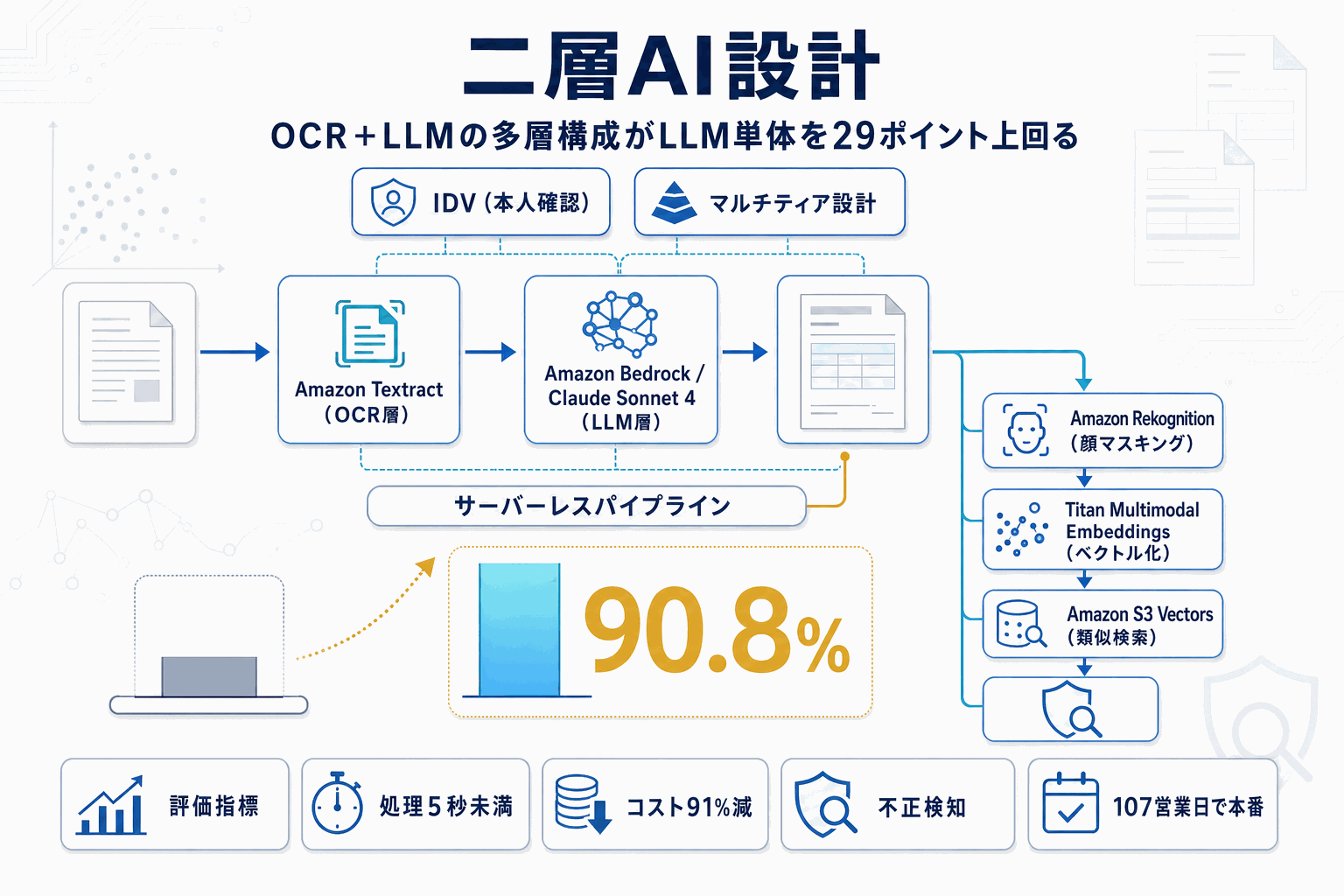
最大のポイントは、同一データでのLLM単体(Claude Sonnet 4で61.8%)と、Amazon Textractによる専用OCRをフロントに置きBedrock上のLLMで構造化する多層構成(90.8%)の精度比較が公開されたことだ。既存の79.7%という基準値も上回り、LLMだけ、OCRだけでは到達できない水準を組み合わせで実現したことが明示されている。
運用面の数字も具体的だ。1件あたりの処理コストは91%削減、処理時間は最大20時間から5秒未満に短縮された。月間8万件のマイクロローン申請のうち約10%が実際の不正申請という規模で回っているため、これは実験値ではなく本番負荷での結果である。PoC開始から本番稼働まで107営業日、Sun Finance側の実装工数は35営業日という導入期間も公開されている。
不正検知側は、Amazon Rekognitionで顔をマスキングしたうえでTitan Multimodal Embeddingsで画像をベクトル化し、Amazon S3 Vectorsで類似検索するサーバーレス構成を採用した。類似背景を使い回す不正申請パターンに対して、生体情報そのものを保持せずに検出する実装パターンを提示している。
日本の金融・保険・行政の本人確認業務にとって、この事例は「どの工程をどのマネージドサービスに割り当てれば、精度・コスト・処理時間がどの水準まで動くか」を具体的数字で比較できる参照点になる。