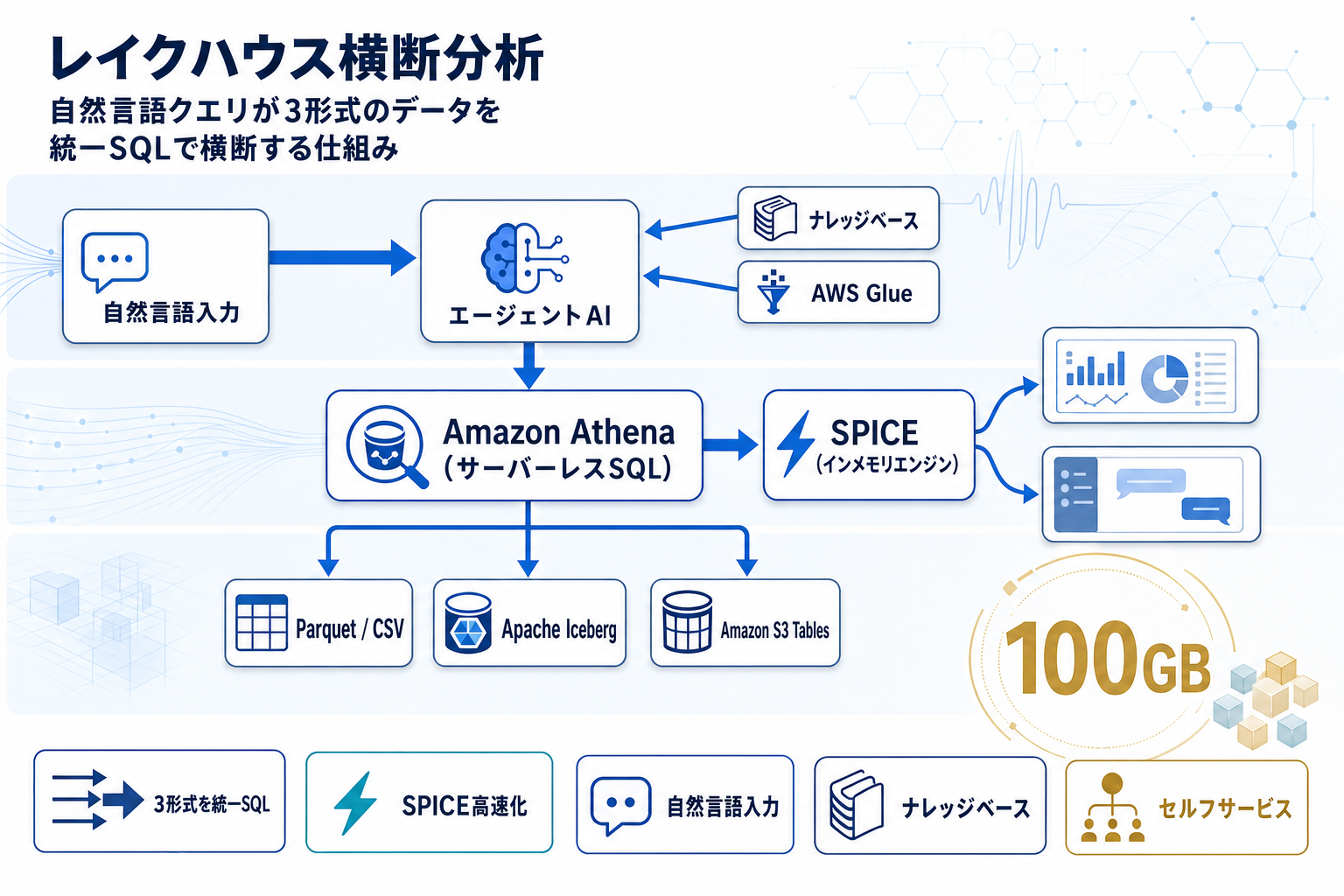
AWS Machine Learning Blogが2026年5月1日に公開した本記事は、Amazon SageMaker・AWS Glue・Amazon S3で構成するレイクハウスに、Amazon QuickのエージェントAIアシスタントを接続する実装パターンを示している。データはTPC-H 100GBベンチマークを用い、CSV・Apache Iceberg・Amazon S3 Tablesという3種のフォーマットでS3に格納される。クエリ層はAmazon Athenaのサーバーレスエンジンが担当し、フォーマットの違いを吸収して統一SQLでアクセスできる構成となっている。
分析UIの側では、Amazon Quickのインメモリエンジン「SPICE」にAthena経由でデータをロードし、従来型のダッシュボードに加えて、会話型チャットエージェントの2系統を提供する。自然言語で問い合わせると、エージェントが適切なクエリを発行し結果を返す流れである。さらにWebクローラーで取得したTPC-H仕様書などの非構造化ドキュメントをナレッジベースに取り込み、エージェントにスキーマや業務用語の文脈を付与する設計が採られている。
日本のAWS利用企業にとっての含意は二つに整理できる。第一に、既にS3+Glue+Athenaでレイクハウスを運用している組織は、基盤を作り直さずにエージェントUIを後付けできる。第二に、Apache Iceberg・S3 Tablesを混在運用する際の参考構成として、統一クエリ層をどこに置くかの設計判断材料になる。一方で、社内データをエージェントに接続する以上、ナレッジベースへの投入範囲と、エージェント応答に対するアクセス制御の線引きは実装側で定義する必要がある。PoCではまず小規模データで応答時間・正答率・SPICEコストを測り、従来のBI運用との比較軸を揃えることが実装順序として有効である。