end-to-end backpropの「メモリの壁」を崩す
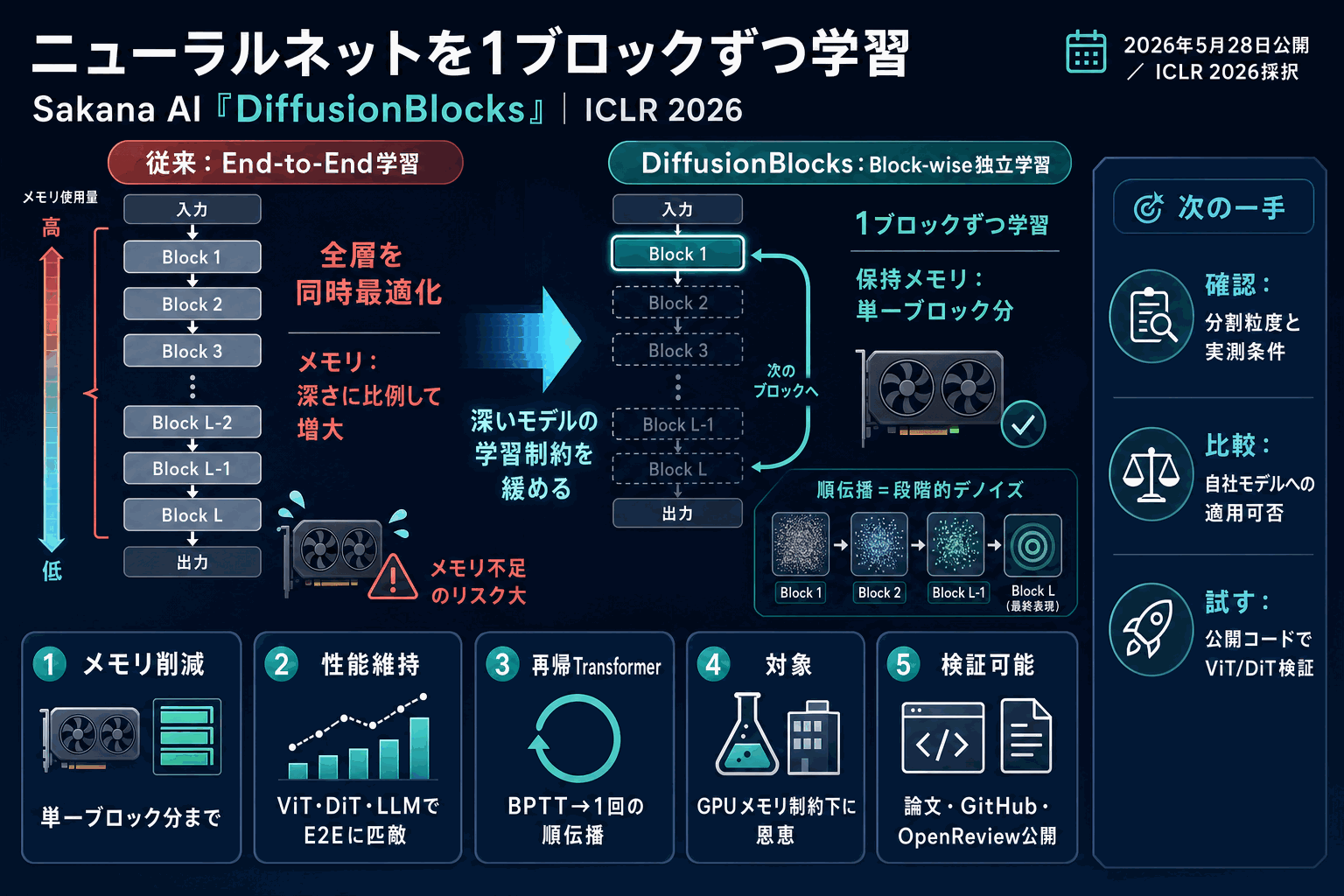
ニューラルネットの学習は10年以上にわたり、ネットワーク全体を一括で勾配計算するend-to-endのバックプロパゲーションを前提としてきた。だが全パラメータを同時に最適化するため、学習時に必要なメモリはネットワークの深さに比例して線形に増える。深いモデルほど計算資源の壁にぶつかる。
Sakana AIが発表したDiffusionBlocksは、この前提を分解する。
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
— Sakana AI Blog
ネットワークをブロックに分割し、1つずつ独立に学習する。そのため学習に必要なメモリは単一ブロック分で済む。
「順伝播 = デノイズ」という再解釈
核となる発想は、各ブロックに「前のブロックより表現を目標へ少し近づける」という明示的な役割を与えることだ。この役割が、拡散モデルがステップごとにシグナルをデノイズする動作と一致する。各ブロックは自分の目的関数だけを最適化すればよく、独立に学習できる。
検証は5種類のアーキテクチャ(ViT・DiT・マスク拡散・自己回帰transformer・再帰深度transformer)で行われ、いずれもend-to-end学習に匹敵する性能を、わずかなメモリで達成したとされる。
とりわけ再帰深度(ループ型)transformerでは、同じネットワークを反復適用するため通常は高コストな時間方向のバックプロパゲーション(BPTT)が必要になる。DiffusionBlocksの視点では、この複数回の反復を学習時に1回の順伝播へ置き換えられる。
論文はICLR 2026に採択され、論文・コード・OpenReviewが公開されている。読者が手元のViTやDiTで再現・検証できる点が、実務判断において重要だ。落とし穴として、ブロック分割の粒度や独立学習の目的関数設計が性能に効くため、公開コードをそのまま流用する前に分割条件とメモリ削減幅を自環境で測ることが必要になる。