なぜ「企業IT運用」専用ベンチが要るのか
コード生成や数学推論のベンチでフロンティアモデルが90%超を叩き出す時代に入っても、企業の情報システム部門が日々向き合うインシデント対応・構成管理・パフォーマンス調査といった運用タスクは、なぜか自動化が進みきらない。理由はシンプルで、これらは「文章を返す」タスクではなく、監視ツールを読み、コマンドを打ち、結果を観測し、副作用を切り分ける一連のループを必要とするからだ。汎用ベンチの数字では、この領域での実力は測れない。
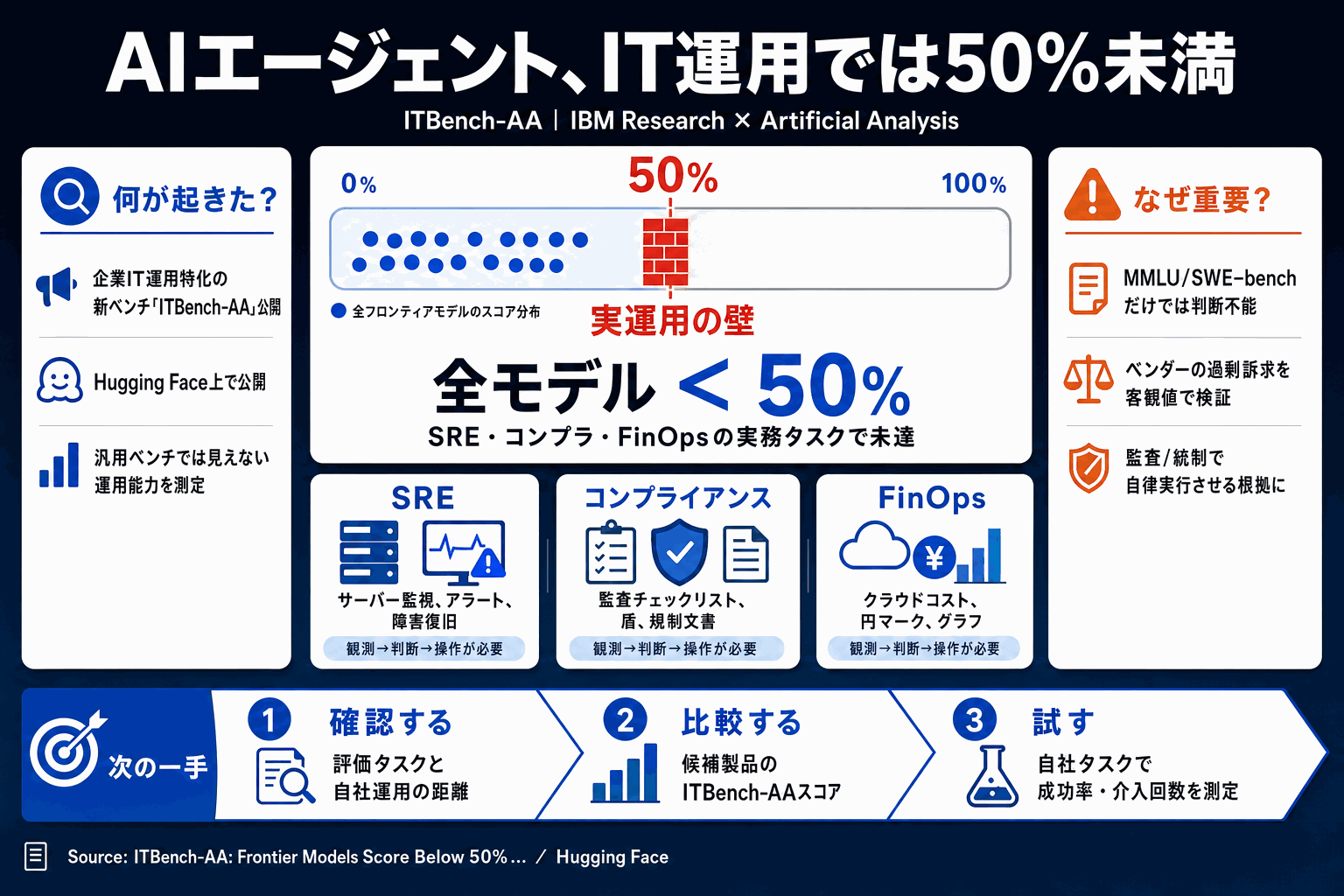
IBMとArtificial Analysisが公開した ITBench-AA は、まさにこの企業IT運用に特化したエージェントタスクを評価する初の公開ベンチマークとして提示された。タイトル自体が結論を含んでおり、フロンティアモデル各社のスコアが 50%未満 に留まったことが明示されている。
「50%未満」が調達会話を変える
この数字が持つ意味は、技術論より調達論の側で大きい。これまで「自律的にIT運用を任せられるAIエージェント」を訴求する製品に対し、購買側は反論の根拠を持ちにくかった。公開ベンチが存在しないため、ベンダー提示のデモと社内PoCの結果だけが判断材料だったからだ。
ITBench-AAが流通すれば、「御社の製品はITBench-AAで何点ですか」という質問が成立する。IBM自身がwatsonxでこの領域に深く関わるプレイヤーであることを踏まえると、評価レイヤを先に押さえに行った戦略的な動きと読み取れる。フロンティアモデル各社にとっては、汎用ベンチの優位が領域特化ベンチでは通用しないことを公に示された格好で、エンタープライズ向けの追加学習・エージェント設計への投資圧力が高まる。
落とし穴: スコアと自社環境の乖離
ただし読者が注意すべきは、公開ベンチのスコアと自社環境での実効性能は必ずしも一致しないことだ。ITBench-AAのタスク定義が自社の運用フロー(監視ツール構成・承認プロセス・復旧手順)とどこまで重なるかは、現場で測り直すしかない。50%未満という数字を「だからまだ早い」と読むか「ここからの伸びしろが大きい」と読むかは、自社運用との重なりを見たうえでの判断になる。