IBM研究所が公開した「The Open Agent Leaderboard」は、AIエージェントの評価が抱えてきた根本的な問題に答えるものだ。これまでエージェントの性能は、論文ごとに異なるベンチマーク・実装条件・指標で報告されており、横比較が事実上できなかった。
今回のリーダーボードはSWE-Bench Verified、BrowseComp+、AppWorld、tau2-Bench(航空・小売・通信の3領域)という性質の異なる6ベンチマークを統一プロトコルで束ね、スコアとコストを並列で可視化する。読み所は3点ある。
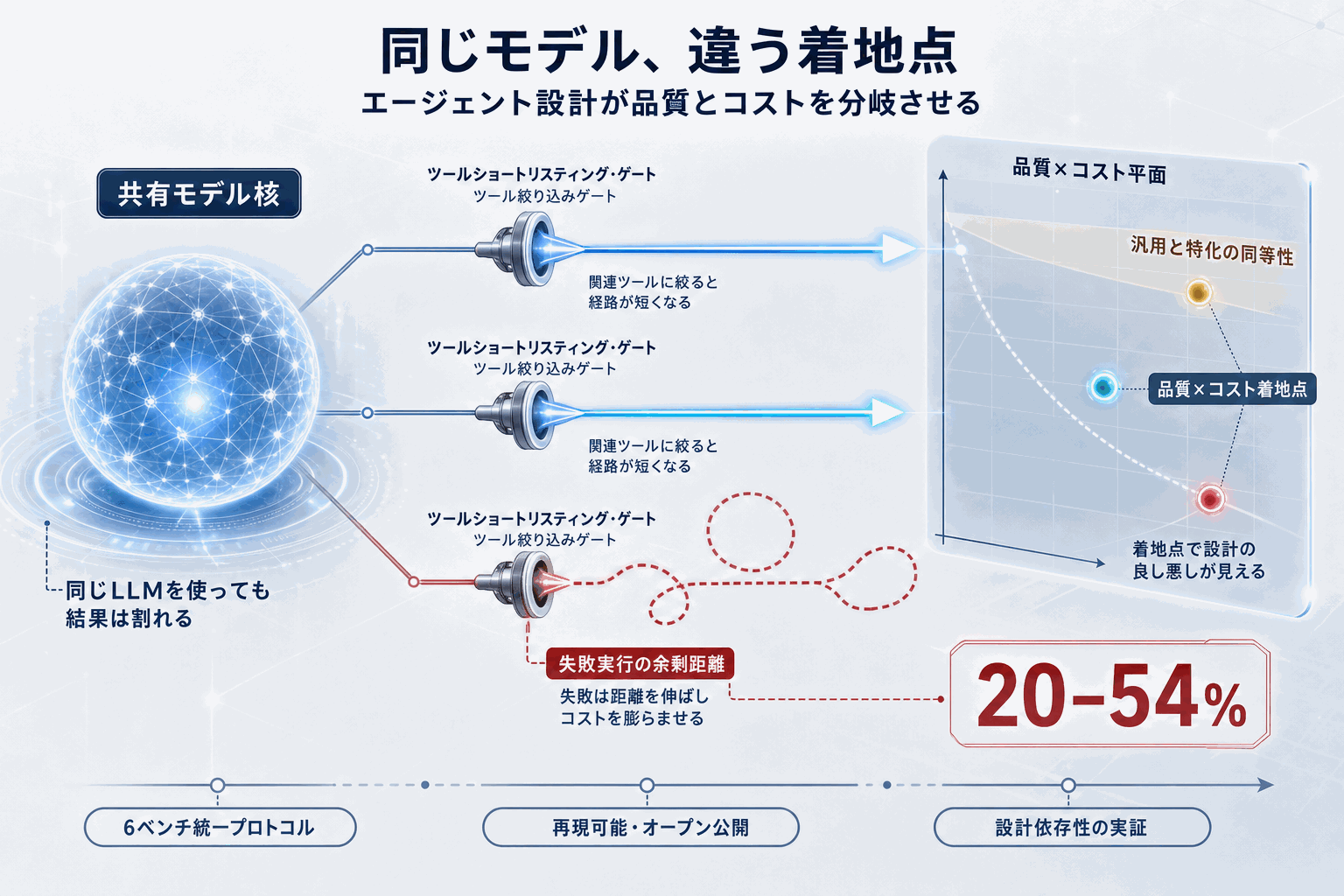
第一に、同一モデルを使う上位3システムでもスコアとコストが分かれた事実だ。これは「どのLLMを採用するか」よりも「どのエージェント設計を組むか」が成果を左右することを実測で示す。第二に、失敗した実行が成功した実行より平均20〜54%コスト高だったという知見。失敗時の長いリトライや暴走的なツール呼び出しがコストを押し上げる構造で、本番運用のリトライ予算・タイムアウト設計に直結する。
第三に、ツールショートリスティング(タスクに関連するツールへの絞り込み)がすべてのモデルで性能を改善し、それ単独で失敗構成を実用可能なレベルへ引き上げた点。汎用エージェントが特化型と同等以上の性能を複数ベンチで達成したという結果と合わせ、「設計のレバレッジ」がモデル選定以上に効くことを示している。
評価資産がオープンで再現可能なため、調達側はベンダー提示スコアの再現性を要件化できる。日本企業がエージェントPoCを評価する際の客観的な物差しとして、即座に活用できる基盤だ。