モデル生成スキルの「効くとき・効かないとき」を切り分ける
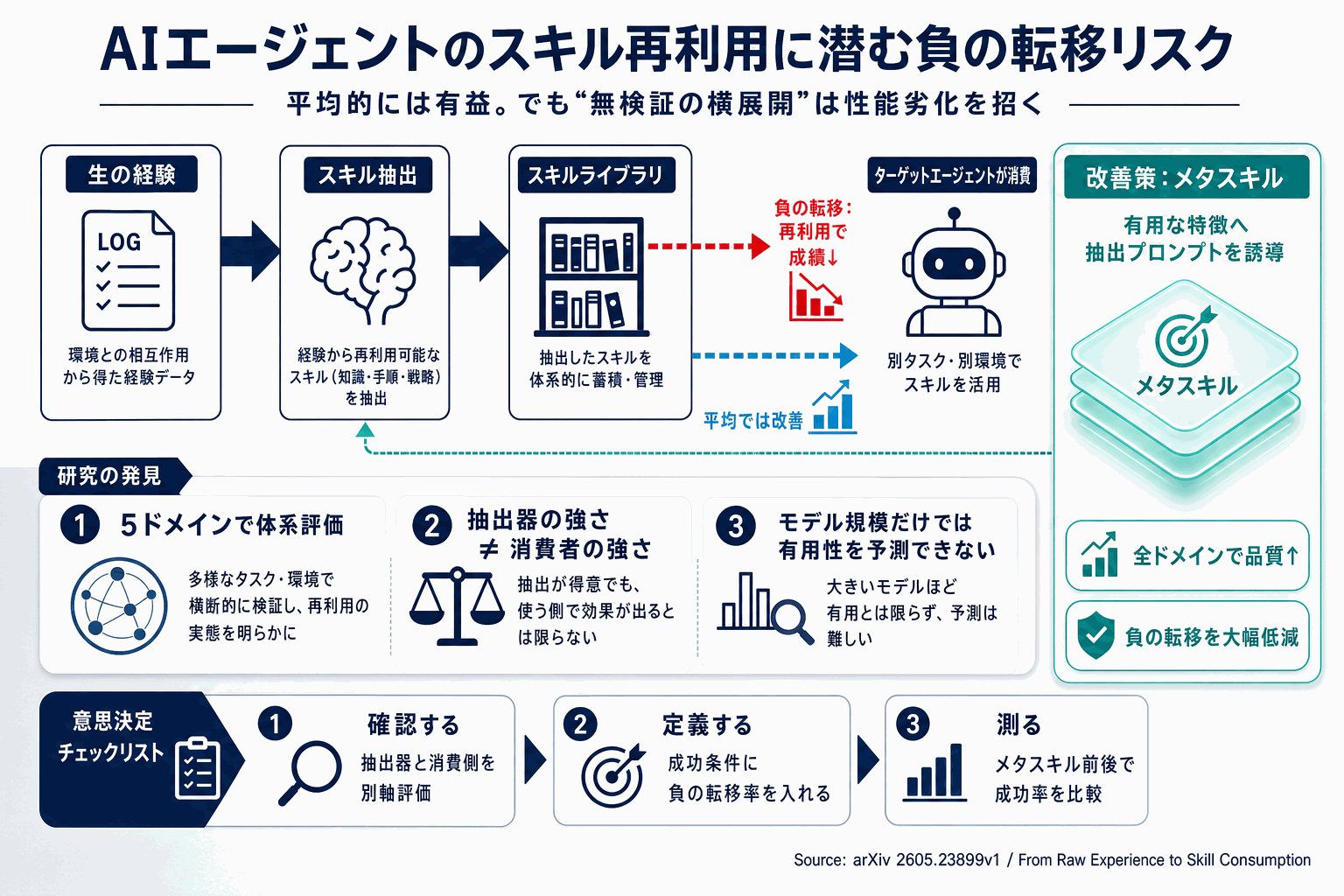
言語エージェントは、過去の経験から抽出した手続き的アーティファクト(スキル)を再利用することで性能を伸ばしてきた。特にドメインレベルかつモデル生成のスキルは、人手作成に比べてスケールしやすく、ドメイン内の反復手順を素早く獲得できる手段として注目されている。しかし論文は、抽出手法だけが増え続け、経験生成→スキル抽出→スキル消費というライフサイクル全体を通した実証研究が欠けていたと指摘する。
本研究は5つの多様なエージェントタスクドメインにわたる「有用性に基づく評価フレームワーク」を構築し、複数の抽出器とターゲットエージェントの組み合わせを体系的に検証した。その結果、モデル生成スキルは平均的には有益である一方、無視できない負の転移が発生することが確認された。
抽出側と消費側の非対称性、そしてメタスキル
注目すべきは、抽出器と消費者の挙動が一様ではないという発見だ。あるモデルは強い抽出器でありながら弱い消費者であったり、その逆もあり、スキル有用性はモデル規模やベースラインのタスク強度から独立していた。これは「大きいモデルを使えばスキルも有効活用できる」という素朴な前提を否定する結果である。
さらに研究チームは、各ライフサイクル段階を深く分解し、経験の構成がスキル品質をどう形作るか、有用なスキルにはどのような特性があるか、同じスキルが消費者を変えてどう転移するかを分析した。これらの知見を、有用性に結びつく特徴へスキル抽出を誘導する具体的な「メタスキル」として翻訳した結果、全ドメインでスキル品質が一貫して向上し、負の転移が大幅に低減されたと報告している。