
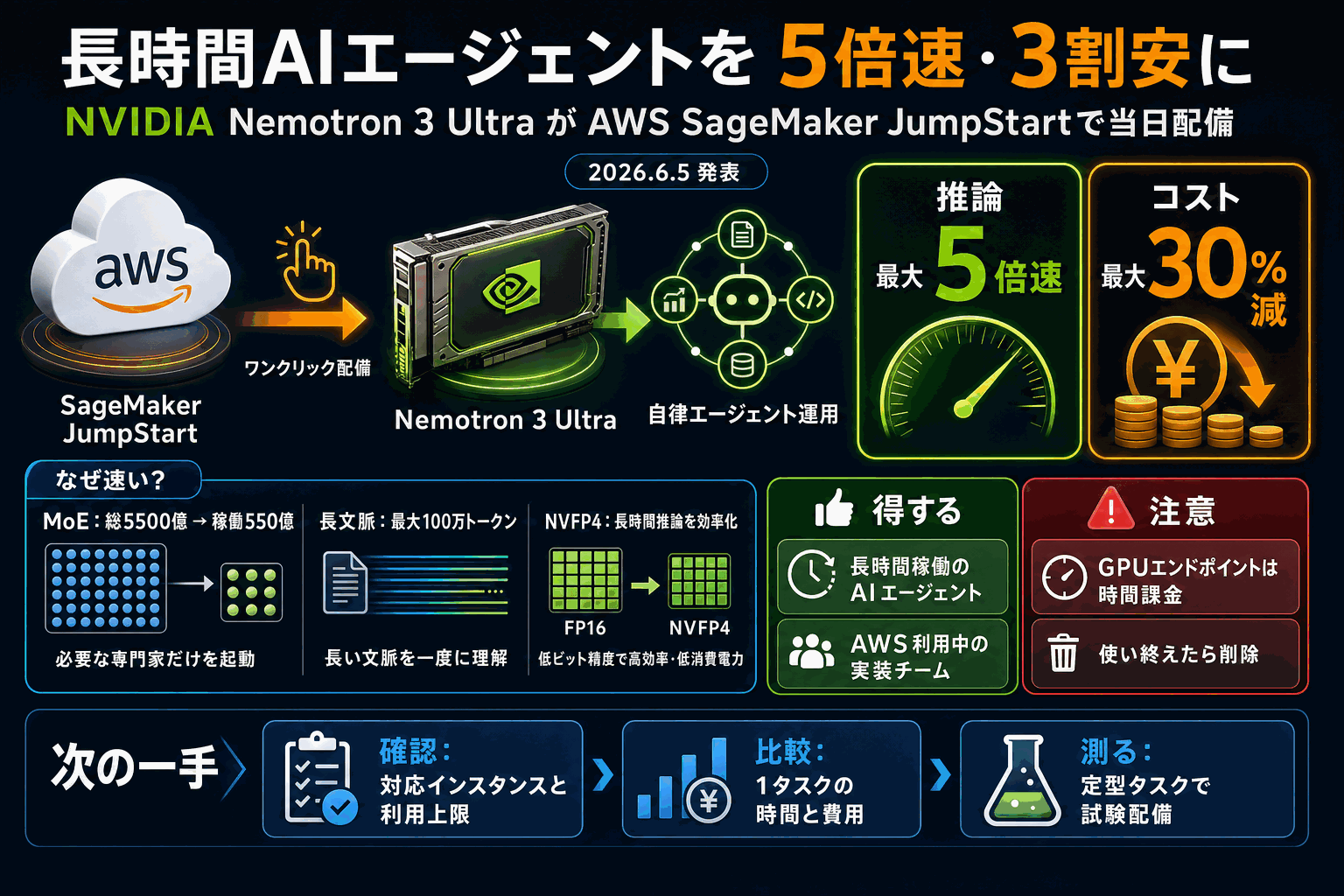
AWSは、NVIDIAの推論特化型大規模モデルNemotron 3 Ultraを、機械学習基盤サービスSageMaker JumpStart上で公開当日から利用可能にしたと発表した。ワンクリックで配備でき、自律エージェント用途で推論を最大5倍速、コストを最大30%削減できるとしている。
モデルは総パラメータ5500億のうち1回の処理で動かすのを550億に絞る混合エキスパート方式(MoE)を採り、最大100万トークンの長文脈を扱う。NVFP4という低精度形式に最適化され、長時間のエージェント処理で速度とコストの両面が効く設計になっている。
配備自体は容易だが、動かす土台はml.p5en.48xlargeなどのGPU専用インスタンスで、稼働中は時間あたりの費用が発生する。試した後に接続点(エンドポイント)を削除し忘れると課金が続くため、コスト管理が運用の前提となる。



OpenAI frontier models and Codex are now generally available on AWS, giving enterprises a new way to build on Amazon Bedrock with OpenAI through the security, compliance, and governance workflows they already use. This is also the beginning of a broader expansion of OpenAI…