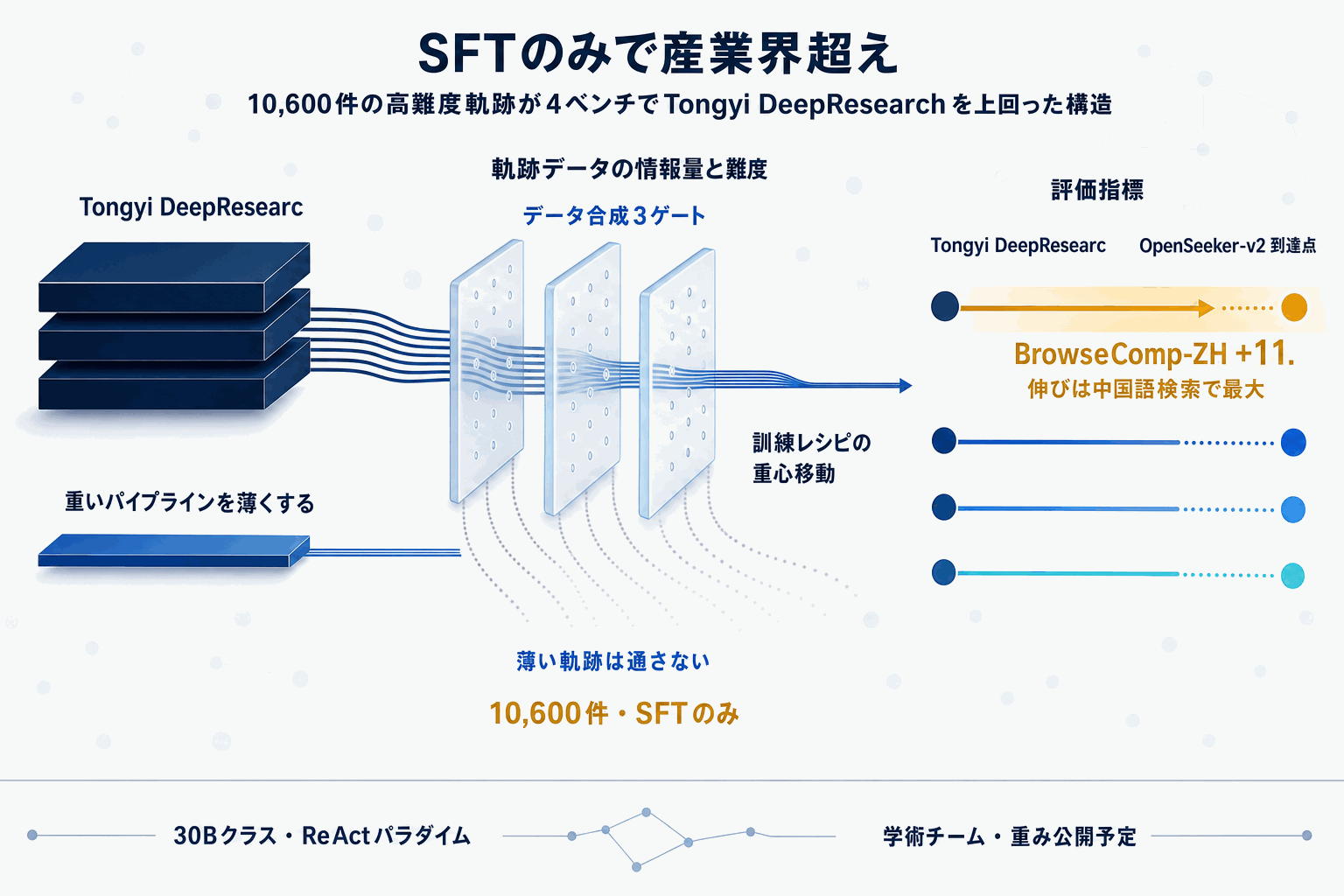
OpenSeeker-v2は、検索エージェント開発の「常識」に対する明確な反証として登場した。従来、BrowseCompやxbenchといった深い検索能力を測るベンチマークで最高水準を狙うには、事前学習・継続事前学習(CPT)・教師ありファインチューニング(SFT)・強化学習(RL)を連結した産業規模のパイプラインが必要とされてきた。Alibaba系のTongyi DeepResearchはその典型だった。
今回の報告は、その前提を3点のデータ合成改良のみで覆している。具体的には、①知識グラフの規模を拡大して探索の多様性を確保する、②ツールセットを拡張してエージェントが扱える機能範囲を広げる、③ステップ数が少ない(=情報量が薄い)軌跡を厳格に除去する、という改良だ。これにより「情報量が多く難度の高い軌跡」だけが訓練データとして残り、わずか10,600件のSFTで4ベンチマーク全てでTongyi DeepResearchを上回った。
数値で見ると、BrowseCompは43.4%→46.0%、BrowseComp-ZHは46.7%→58.1%、Humanity's Last Examは32.9%→34.6%、xbenchは75.0%→78.0%と、特に中国語検索タスクで大きな伸びを示している。30Bクラス・ReActパラダイムという制約下での比較である点も、実務適用時のコスト感と直結する。
注目すべきは、これを純粋な学術チームが達成した点だ。RLパイプラインの運用コストを負担できない研究者や小規模組織にとって、「データの質を磨けばSFTのみで届く」という具体例が公開された意義は大きい。モデル重みのオープンソース公開予定と合わせ、検索エージェント研究の参入障壁を構造的に下げる一本となる。