IBMがHugging Face上で公開したGranite 4.1 LLMsの技術解説記事は、モデル配布と同時に構築パイプラインの内部を詳細に開示した点で、オープンソースLLMの中でも情報密度が高い。
ラインナップは3B・8B・30Bの3サイズで、いずれもApache 2.0ライセンス。特に注目されるのは8Bインストラクトモデルが、旧世代のMoEモデルであるGranite 4.0-H-Small(32B-A9B)と同等以上の性能を達成した点だ。密モデル側でMoEを追い抜いたことは、推論時のGPUメモリ要件とスループットの設計に直接影響する。
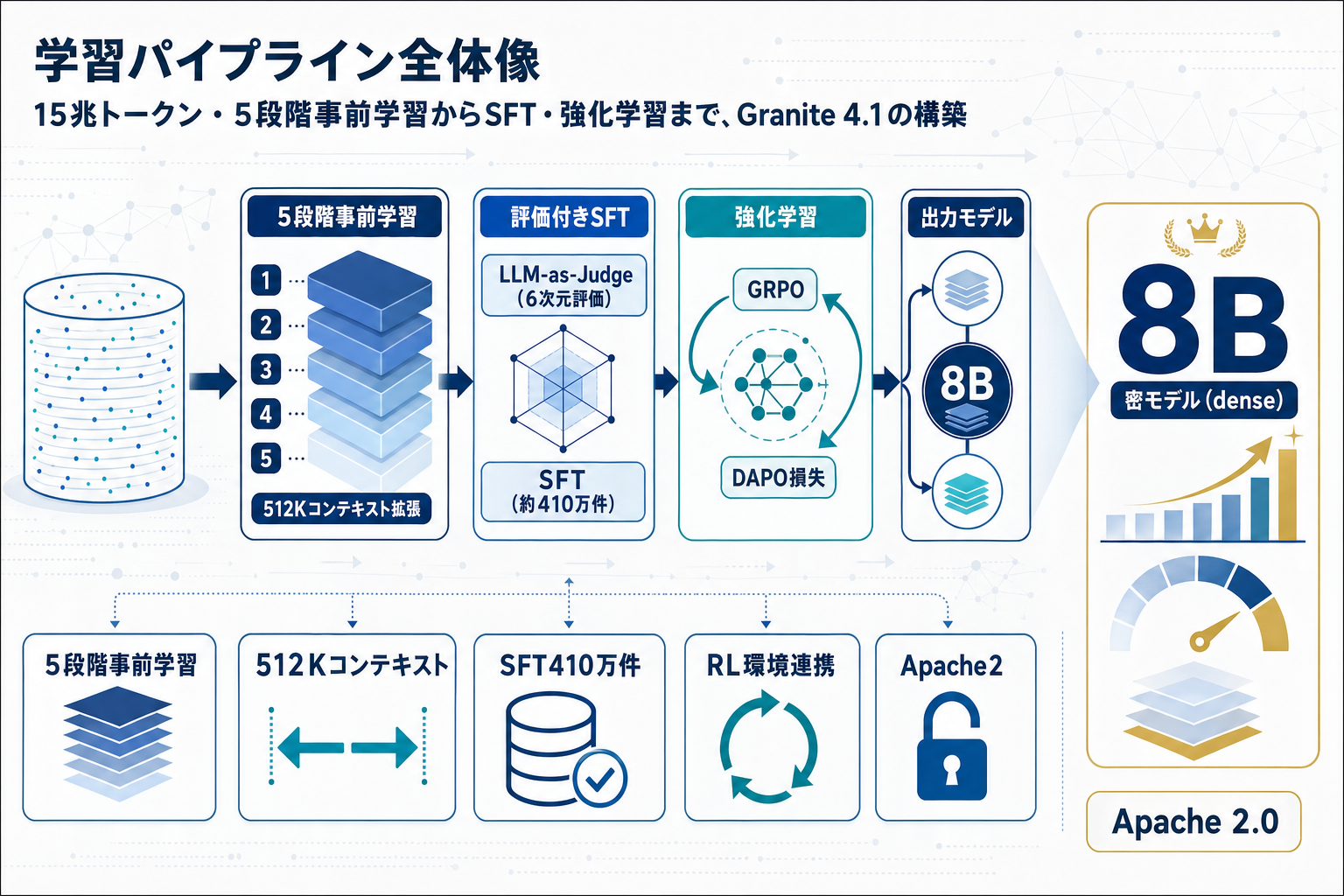
事前学習は約15兆トークンを使った5段階パイプラインで構成される。最終段階でコンテキスト長を512Kトークンまで拡張しており、長文RAGや契約書・コードベース全体を扱う用途での前処理設計を簡素化できる。
ポストトレーニングでは、約410万件の高品質サンプルを用いたSFTをLLM-as-Judgeフレームワークで6次元(指示遵守・正確性・完全性・簡潔性・自然さ・校正)評価している。強化学習はオンポリシーGRPO(Shao et al., 2024)にDAPO損失(Yu et al., 2025)を組み合わせ、数学・コーディング・指示遵守・一般チャットを強化した。
日本のエンタープライズにとっては、Apache 2.0で商用利用が自由な点、3サイズでオンプレ・エッジ・サーバの構成を柔軟に組める点、そして構築手法が文書化されているため社内審査やモデルカード要件に応えやすい点が意思決定に効く。8Bで32B級MoEを代替できる前提が自社タスクで成立するかは、評価セットでの実測が次の一手になる。