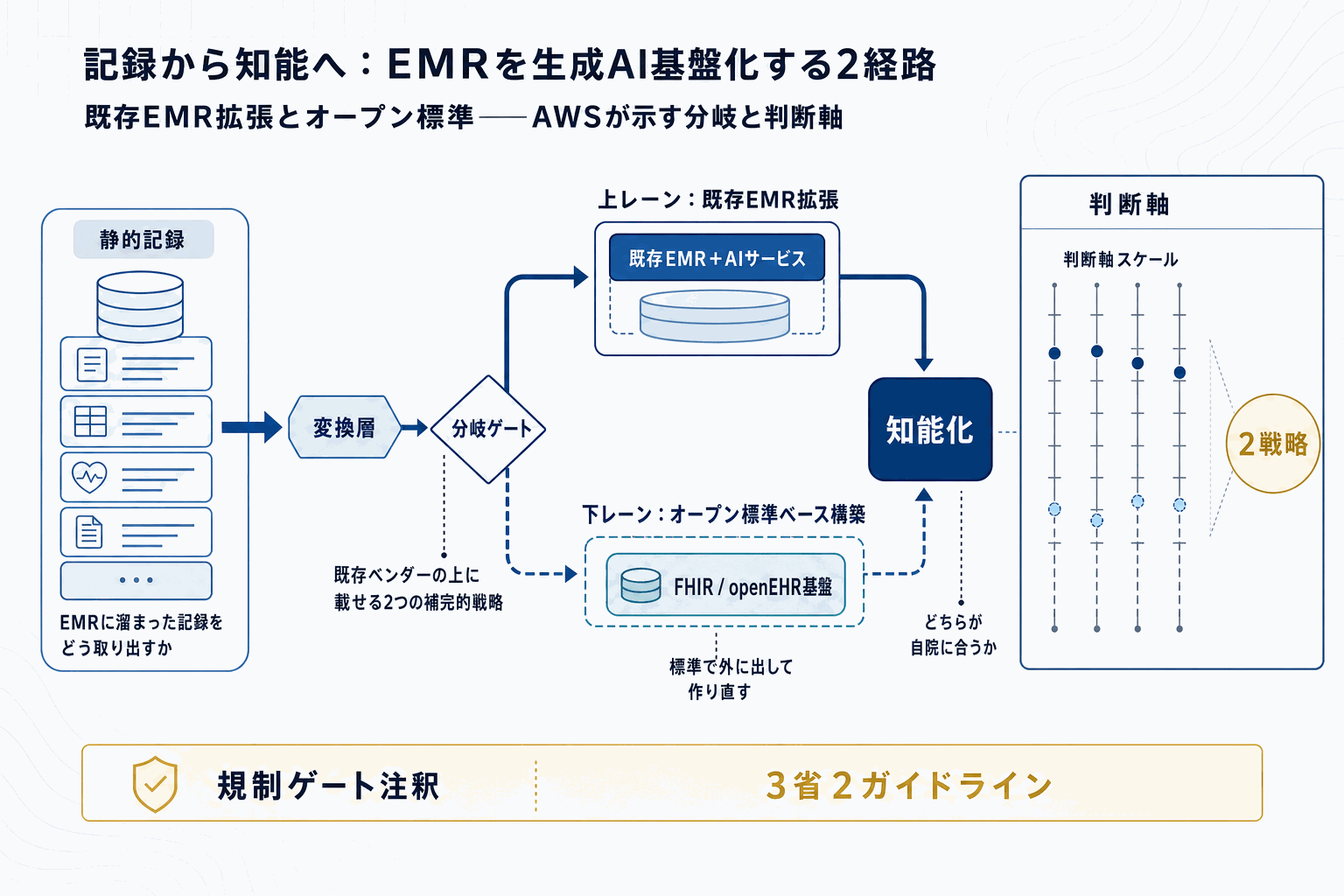
AWSは公式のIndustries Blogで、AWS上に構築された電子カルテ(EMR)システムを、静的な臨床記録の保管場所から生成AIの基盤へと進化させるための考え方を整理した。提示されたのは2つの補完的な戦略である。1つ目は、既存のEMRシステムにAWSのAIサービスを組み合わせて機能を拡張するアプローチで、いまある資産を活かしながら段階的にAI機能を載せていく方式にあたる。2つ目は、FHIRやopenEHRといったヘルスケア領域のオープン標準の上に基盤を構築するアプローチで、データの相互運用性と長期的な可搬性を重視する方式となる。
日本の文脈で見ると、電子カルテは依然としてベンダーごとの独自仕様が強く、データ連携や二次利用の壁が指摘されてきた領域である。AWSが2戦略を併記したことは、既存EMRに後付けするか、標準ベースで作り直すかという調達判断の軸を、グローバルなクラウド事業者の視点から整理した意味を持つ。生成AIの活用が前提となるほど、データ側の設計(どの標準で保持し、どう抽出するか)が成果を左右する。
ただし、本記事はAWSによる単一ソースの方針提示であり、具体的な顧客事例や数値、コスト比較は今回の公開情報には含まれていない。読者が判断するうえでは、自院・自社の現行EMRがFHIRやopenEHRにどこまで対応しているか、AI機能をどの業務(要約、コーディング支援、患者対応など)に当てるかを定義したうえで、2戦略のどちらが現実的かを切り分ける必要がある。標準ベースは将来の移行コストを下げる一方、初期実装の負荷は大きい。逆に既存EMR拡張型は早く動かせるが、ベンダー依存が残る。