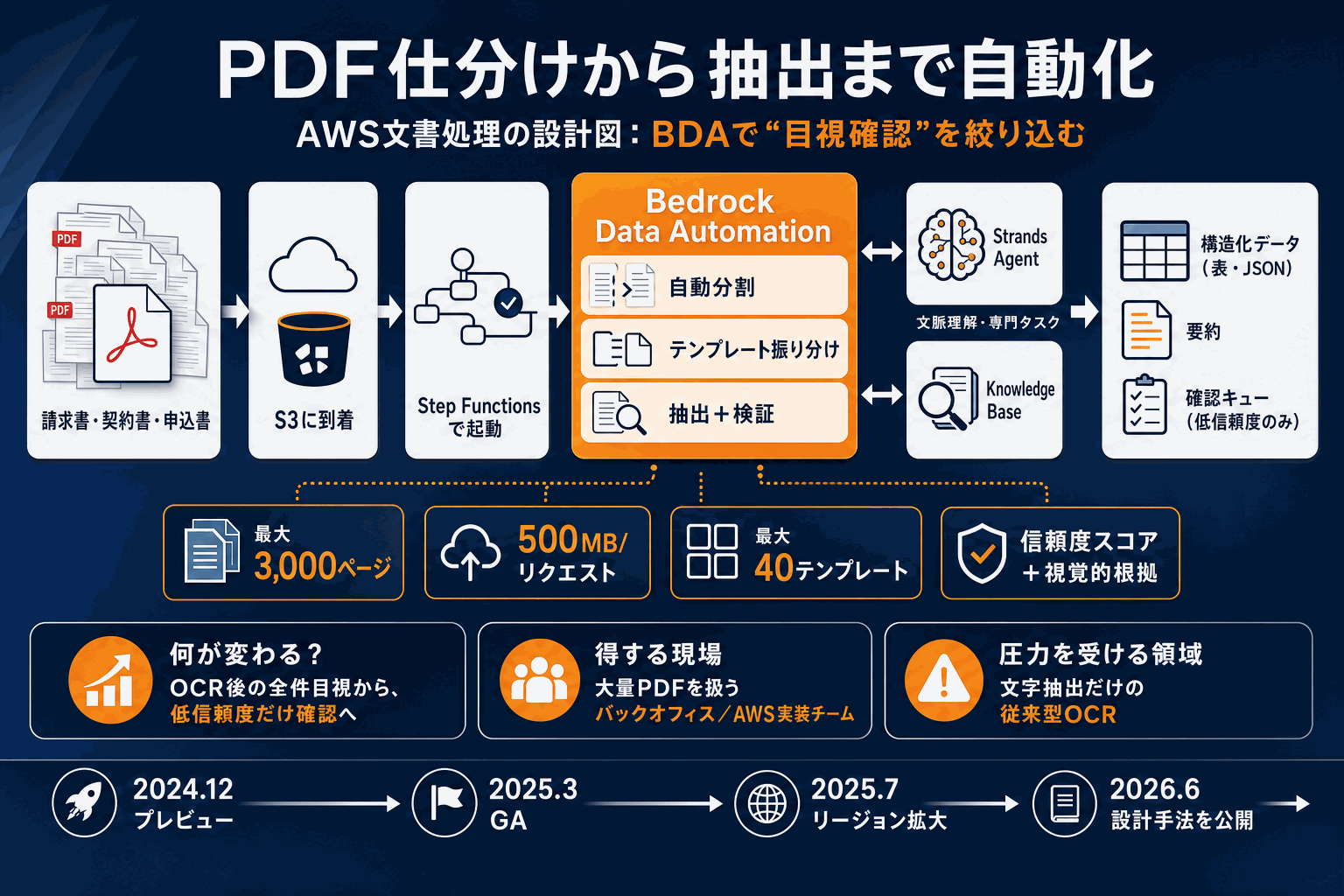
AWSは2026年6月12日、PDFや契約書から構造化データを自動抽出する文書処理パイプラインの設計手法を公開した。中核に据えたのが、文書の分割・分類・抽出・正規化・検証を1つの窓口で扱うマネージドサービスAmazon Bedrock Data Automation(BDA)だ。BDAが文書を抽出・分析し、Strands Agent(AgentCore Runtime上で動作)が専門タスクの連携を指揮、Knowledge Baseが複数文書をまたぐ文脈理解を担う構成になっている。
BDAが従来型OCRと異なるのは、文字抽出だけでなく視覚的根拠と信頼度スコアを返す点だ。これにより人手確認が必要な箇所を絞り込める。1リクエストで最大3,000ページ・500MBまで対応し、論理的な区切りで自動分割(1分割最大20ページ)する。1プロジェクトに最大40種類のテンプレート(ブループリント)を登録し、文書を自動振り分けできる。
処理はAWS Step Functionsが統括し、S3への文書到着を起点にサーバーレスで大量処理する。BDAは2024年12月にプレビュー、2025年3月に一般提供を開始し対応リージョンを拡大してきた。今回はこれらを束ねた設計図を提示した点に意味がある。