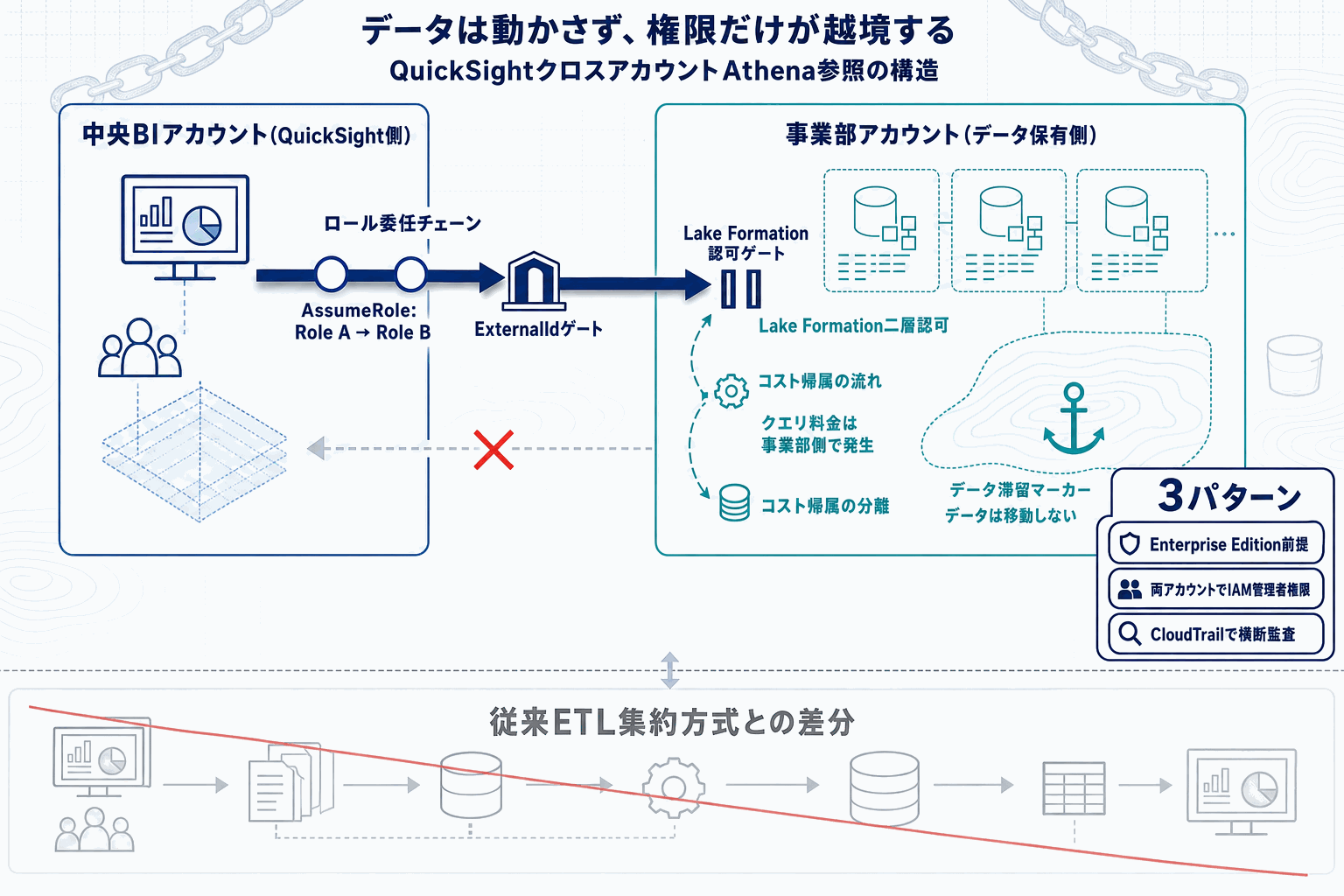
AWSは2026年5月15日付のMachine Learning Blogで、Amazon QuickSightから別AWSアカウントに置かれたAmazon Athenaのデータへ直接アクセスする構成パターンを公開した。マルチアカウント戦略を採る組織では、事業部・子会社ごとにAWSアカウントを分離し、それぞれがS3とGlue Data Catalogでデータレイクを保持するケースが一般的だが、経営ダッシュボードや横断KPIを作る段階で「どこに分析基盤を置くか」が課題になっていた。
従来の典型解は、中央の分析用アカウントへS3レプリケーションやGlueジョブでデータを集約し、そこにQuickSightを置く方式だった。今回の手順は、各データ保有アカウントのAthenaワークグループに対しIAMロール委任で参照権を与え、QuickSight側はそのロールをAssumeしてクエリを発行する形を取る。データ本体は移動しないため、ストレージの二重保持と同期遅延の問題を避けられる。
読者が実装着手時にハマりやすいのは、IAMロールの信頼ポリシーとLake Formation権限の二層構造である。IAMで通っても、Lake Formationが有効なカタログでは別途データロケーション・テーブルへのGrantが必要になる。また、QuickSightのサービスロールが想定どおりにAssumeRoleできるか、SPICE取り込みとダイレクトクエリで挙動が一致するかは事前の検証対象となる。
コスト面では、ETLパイプライン削減と引き換えにAthenaクエリ料金が発行元アカウント側に発生する点を会計上どう扱うかの設計が必要になる。公開数値はないが、月次レポート用途であれば集約用ストレージとGlueジョブを廃止できる効果は実装規模次第で見合う水準になる。